
Workflows
If you want to see the API specs, click here.
This product (workflow) is named after its core entity, i.e. workflows. A workflow defines steps that are executed based on some frequency, e.g. every second. For instance, a workflow to pull data from an inbox, which is then processed via a gates endpoint, and ultimately fed back for categorization or similar.
Workflow options
In workflow, you can define two types of processess: realtime (i.e. operational) and batch (i.e. analytical) workflows. They differ in a very simple way:
realtime: are executed per item, and can be executed e.g. every secondbatch: technically also work on item-level, but they are executed on batches of data, and can be executed e.g. every day. This higher level of granularity makes them perfect for analytical jobs.
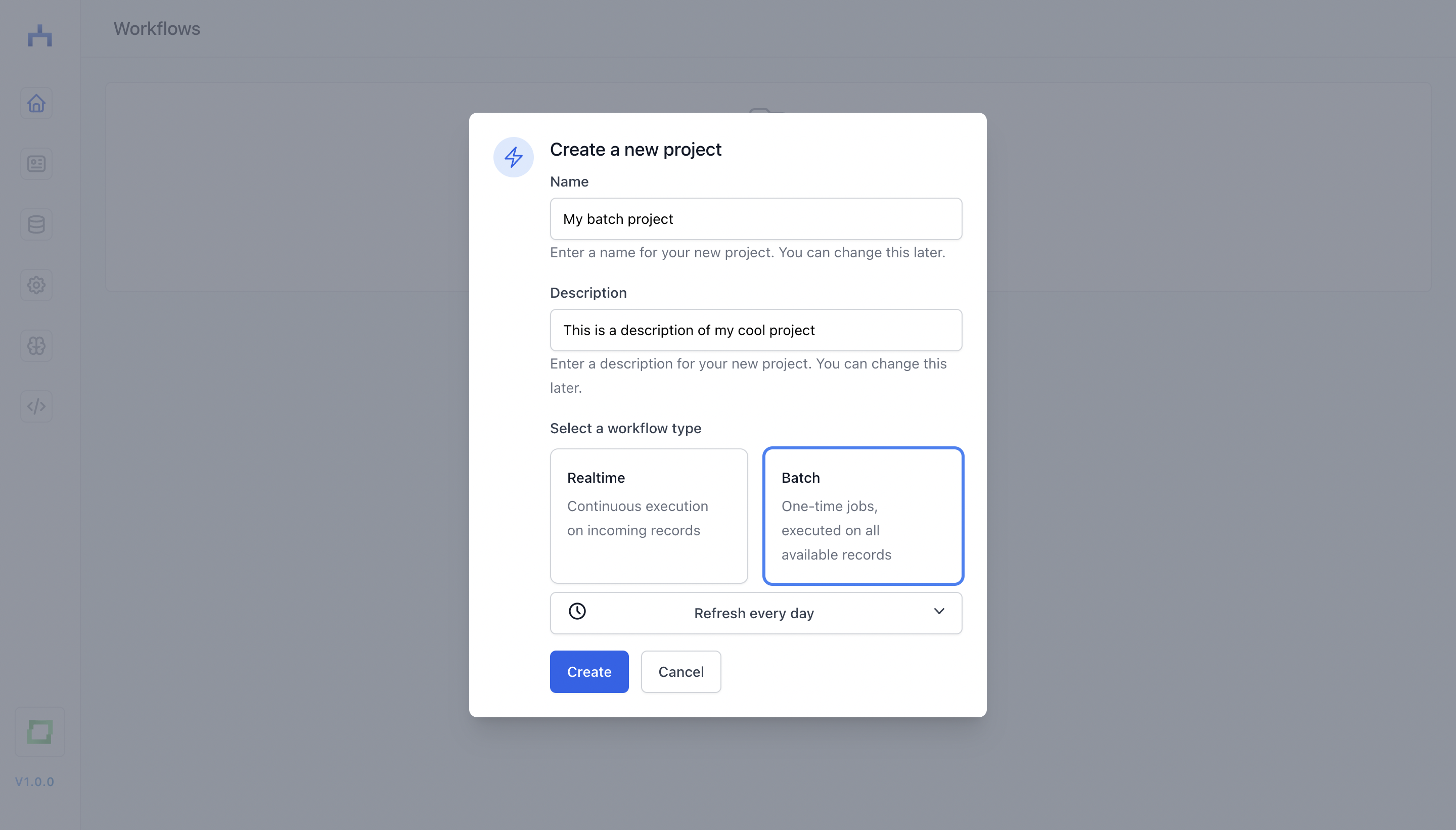
When to choose which depends on your use case. In most cases, starting with a realtime job makes perfect sense.
The canvas
The canvas is your drag-and-drop editor in workflow.
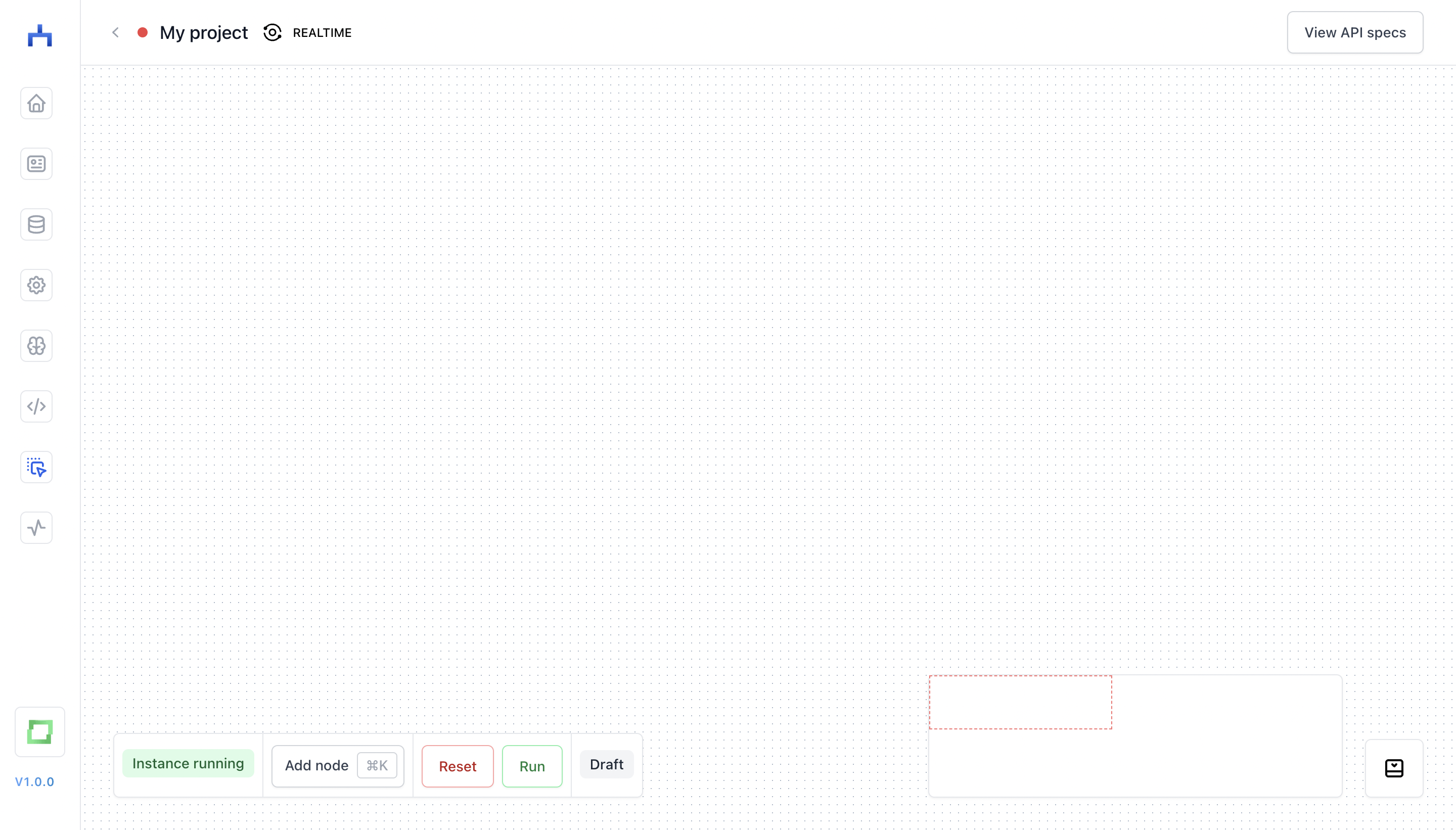
In this canvas, you can hit ⌘ + K or hit the Add node button in the left bottom control section. This will open up a scrollable and filterable node palette for you.
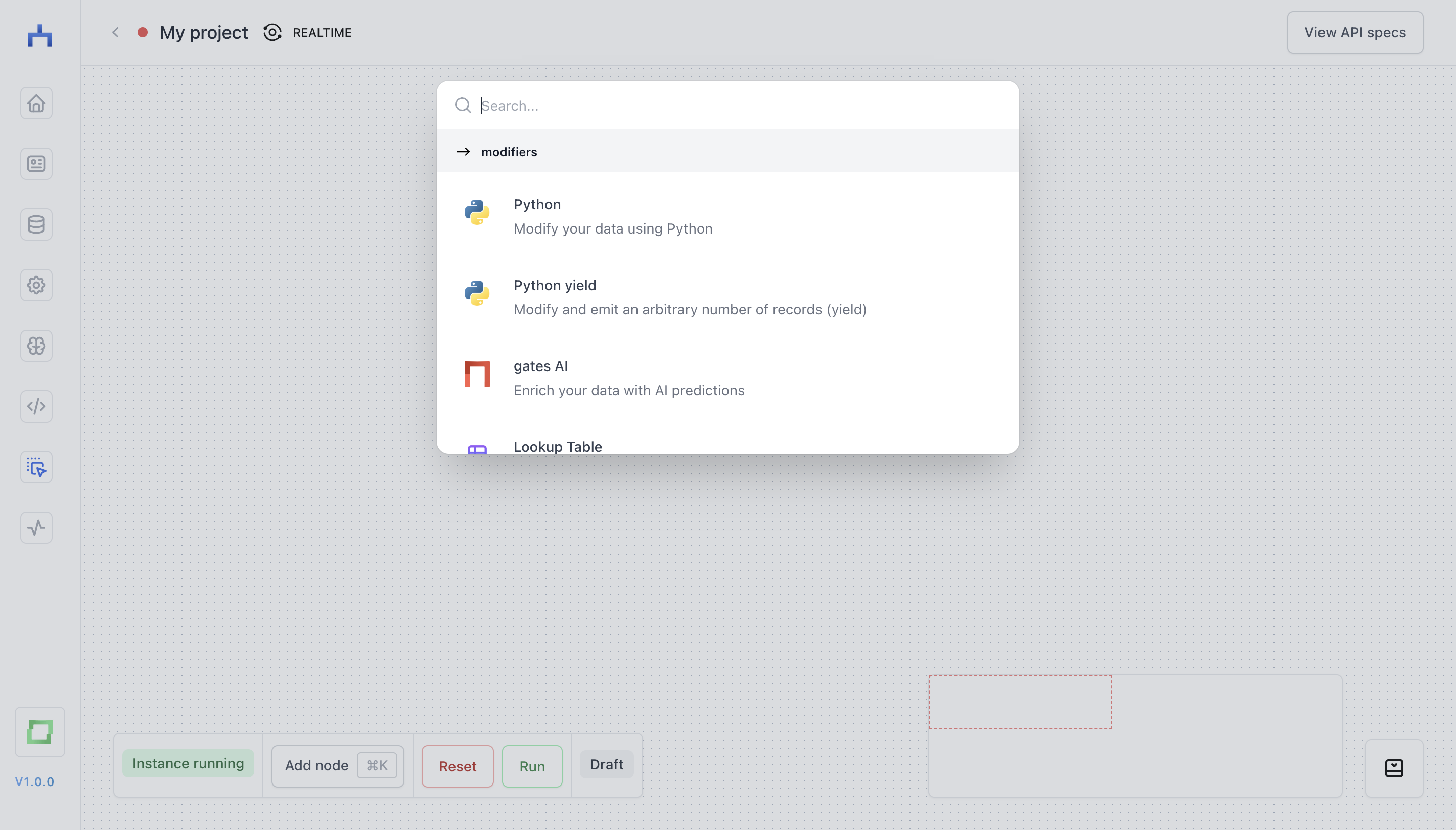
The node palette
The node palette is divided into three categories: sources, modifiers and targets. You can find more details about these categories on the stores page. We will cover each category with an example now.
Source nodes
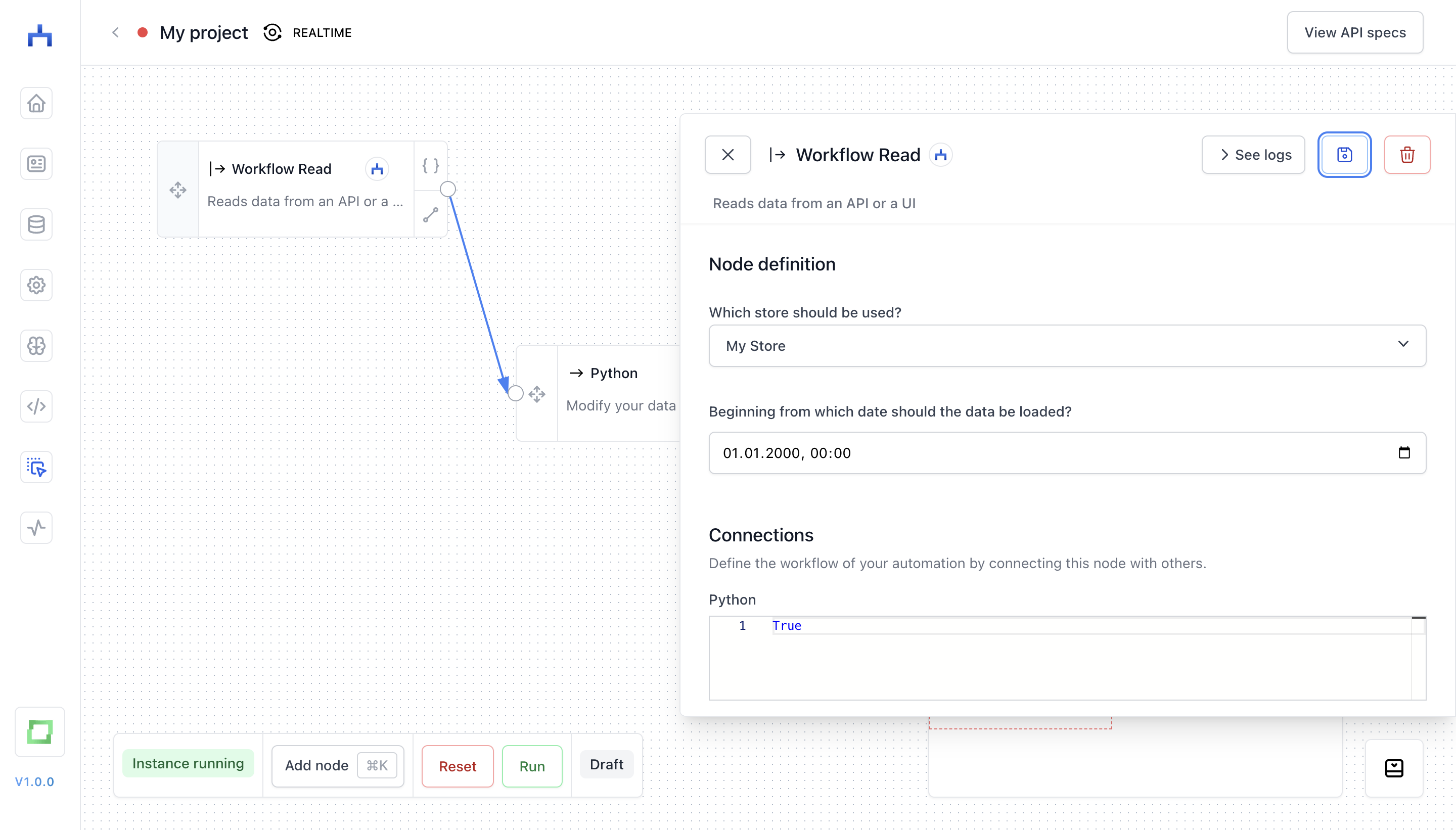
A source grabs data from a store that you've set up (if you are not sure how to do so, look into the store page). For instance, you can set up a "Workflow Read" store, and then use the "Workflow Read" node.
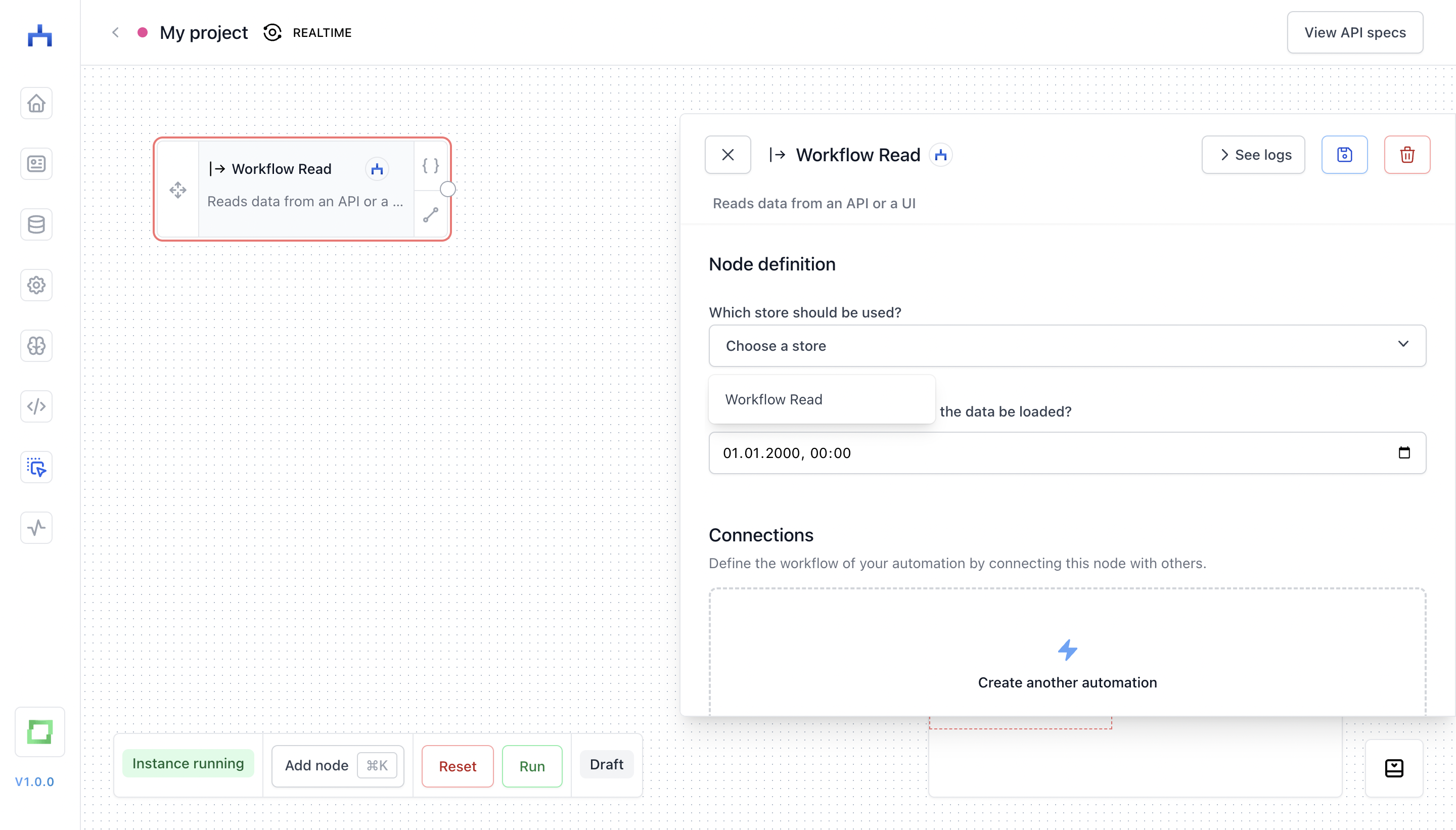
If a node has a red border, it means that you haven't configured the node yet. Simply click on it, and finish its configuration (most of the times this just means selecting a store).
When you fetch data from a store node during a workflow, a marker will be set in the database which remembers to not pull the entry anymore for this specific workflow; in other words, every entry in a store node will only be fetched once by a workflow. As this marker is store-workflow-specific, it means that you can pull the same entry from a store in multiple workflows. If you Reset the workflow, all markers for this store-workflow-combination will be removed, meaning you can pull all entries again.
In other words: when you're developing a workflow and noticed that you made a mistake in some Python logic, you can simply reset the workflow and start over. Caution: Data that you send to a store as a result of a workflow will not be removed by hitting Reset!
Modifier nodes
A modifier node is inbetween two other nodes in a workflow; it takes a record (:dict) as input, and returns either exactly one record, or yields an arbitrary amount of records. A simple example is the "Python" node.
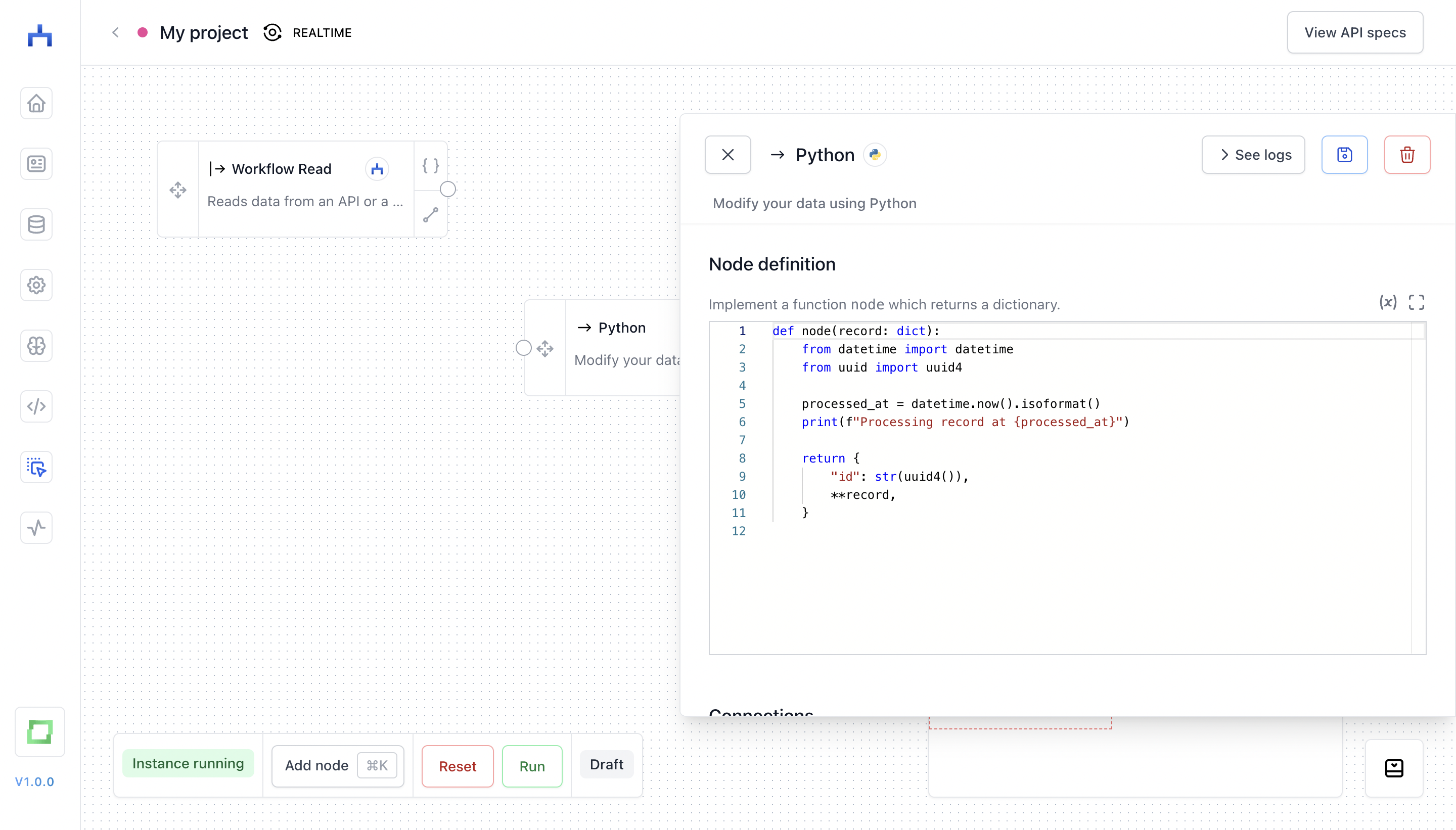
Alternatively, you can also use a loop of the "Python" node, which comes in handy when you e.g. want to webscrape a page and yield multiple records per scraped page:
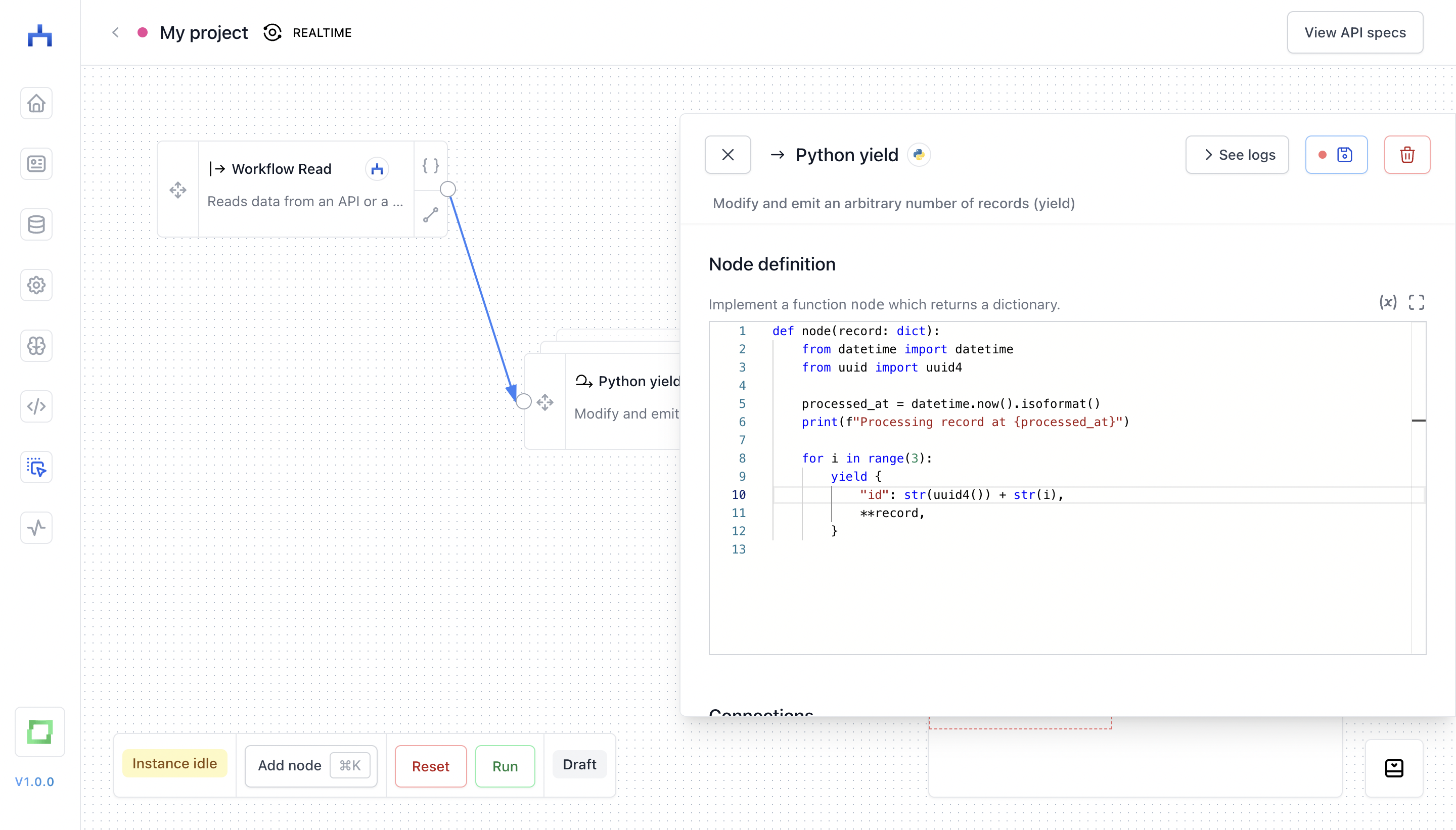
Target nodes
A target node is triggering an action when a new entry is put into it. For instance, you can set up a "GMail Send" store which tries to create a draft for an existing message, and which categorizes emails based on some previous logic. To make sure that no action is triggered twice, all target nodes expect a unique id. In simplest cases, this can be something like a uuid, but generally it must be unique. If a store requires other fields (e.g. draft or category, it will tell you so in the configuration screen).
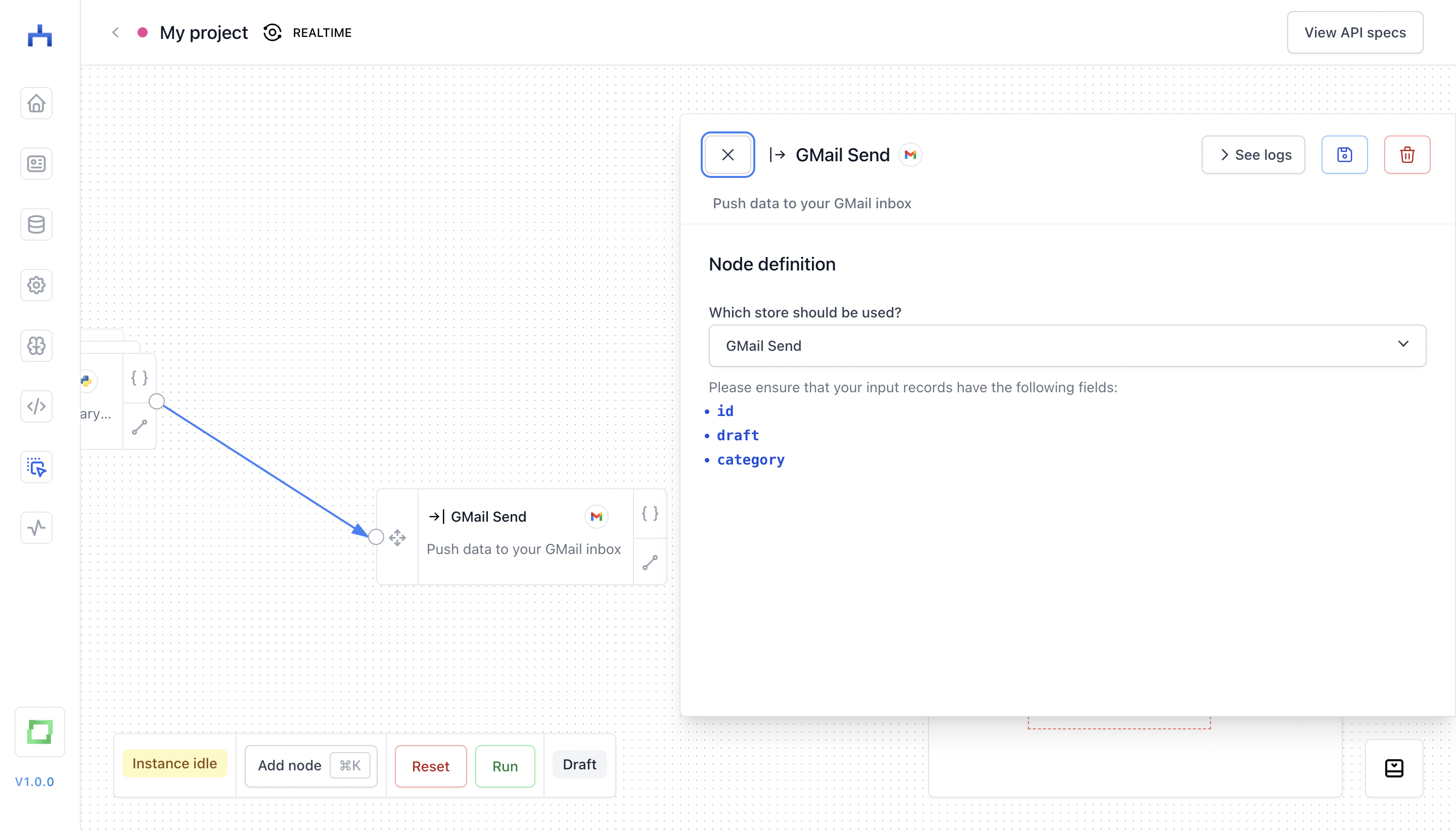
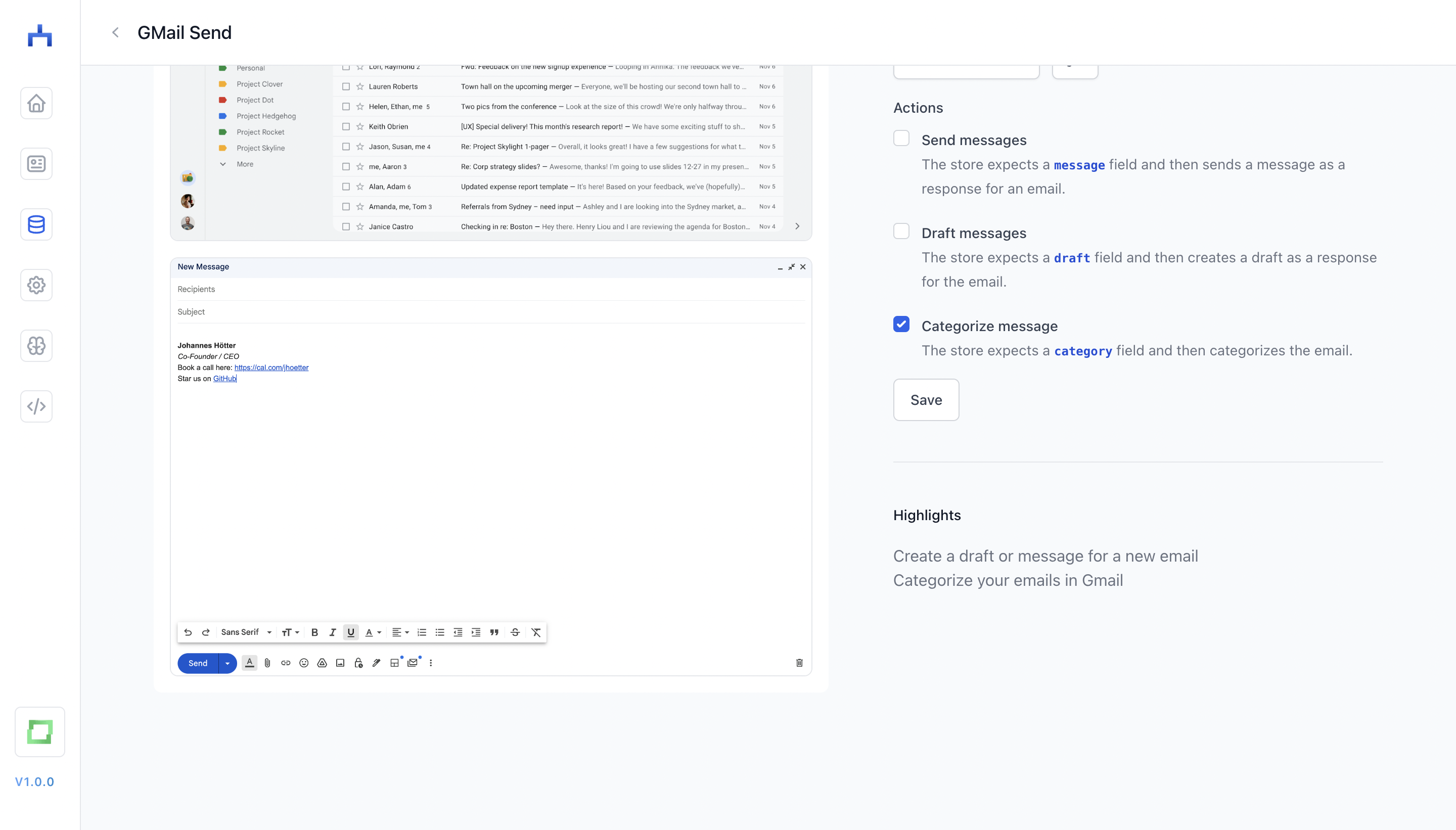
Which actions are triggered by the store can occasionally be configured in the store creation page. For instance, for the "GMail Send" node, you can define whether you rather want to draft messages, or directly send messages.
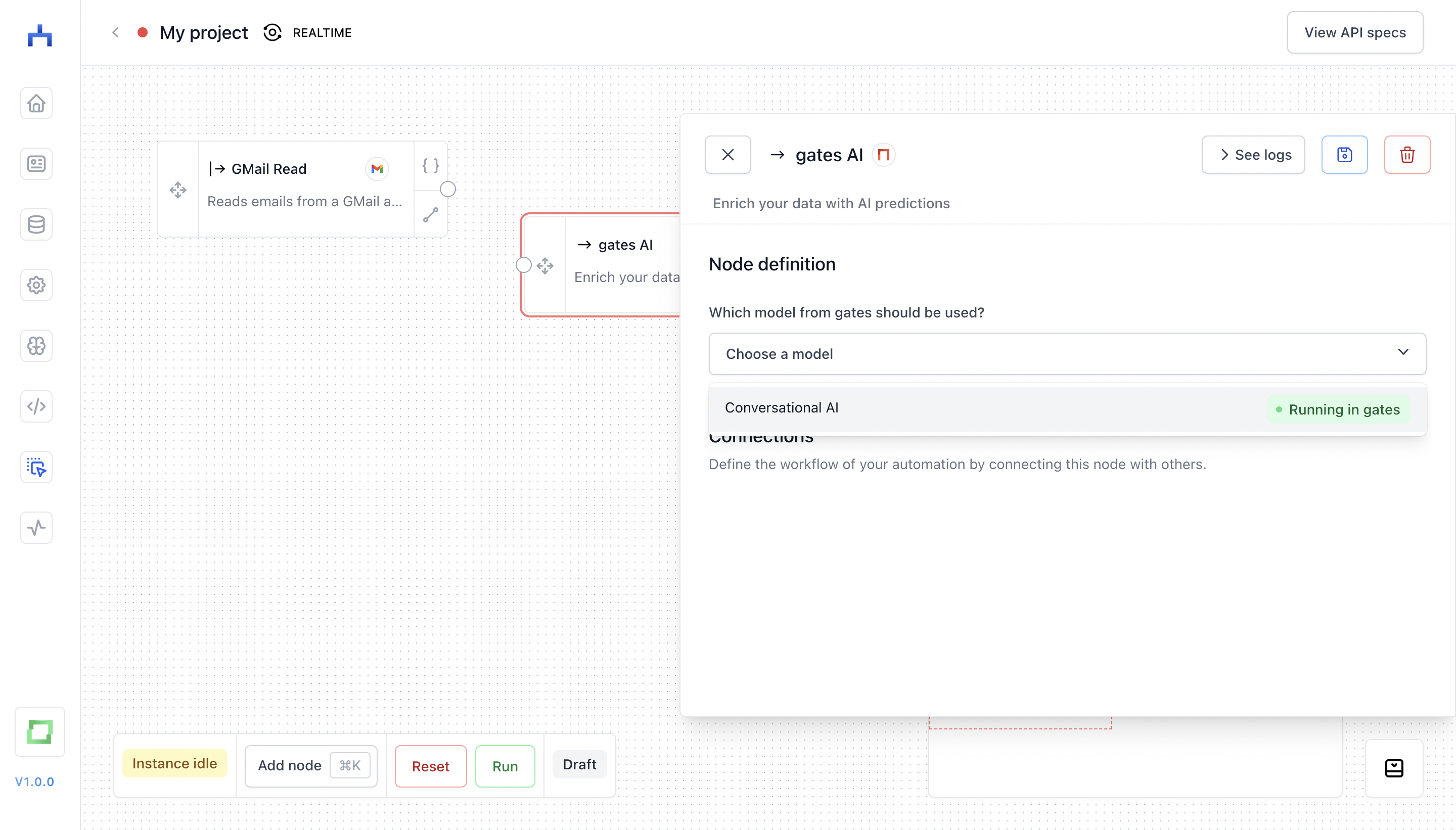
gates AI node
gates is natively integrated in workflow, and you can use any gates model that is running as a modifier node.
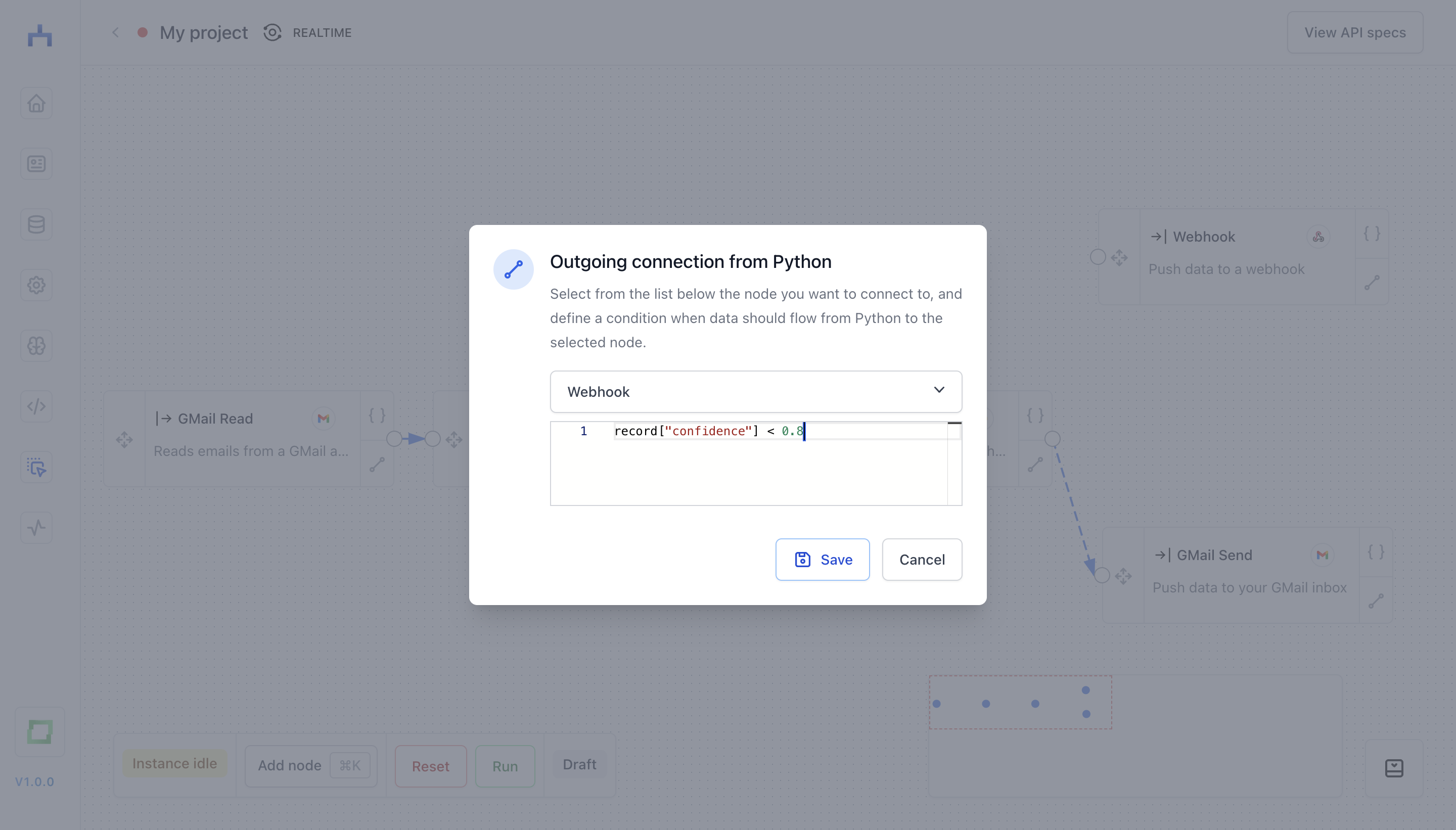
Connecting nodes
The way to connect nodes in workflow is to write Python conditions. Something you would write immediately after an if keyword, e.g. if record["confidence"] > 0.8: would be record["confidence"] > 0.8 in a node connection. If you want to forward data in any case, just type True into the node connection.
We're drawing edges between nodes on a simple logic:
If a condition is
True, we draw a solid line. We don't evaluate the condition in advance, i.e. this is only the case if the box contains the actual wordTrueand nothing else.If a condition is
False, we don't draw a line at all. Again, this is a hard string-match.- For everything else, we draw a dashed line.
Technically, you could draw a dashed line by entering 1 into the conditional field, which logically for Python is equivalent as True for conditions. But we encourage you to simply use True :)
You can also create a node via our quick connection modal. Click on the bottom right icon of a node container to open the modal:
Running a workflow
You can run a workflow by clicking Run in the bottom left command palette. Every running workflow is encapsuled in a Docker container. If you hit Run, a container will be activated within few seconds.
Logging nodes
Inside a "Python" node, you can write some simple print logic to log what your node is doing. In addition, you can also look into what output your node creates. This is especially helpful while you are implementing a workflow, as you can gradually look into results of a node before attaching it to a final target store.
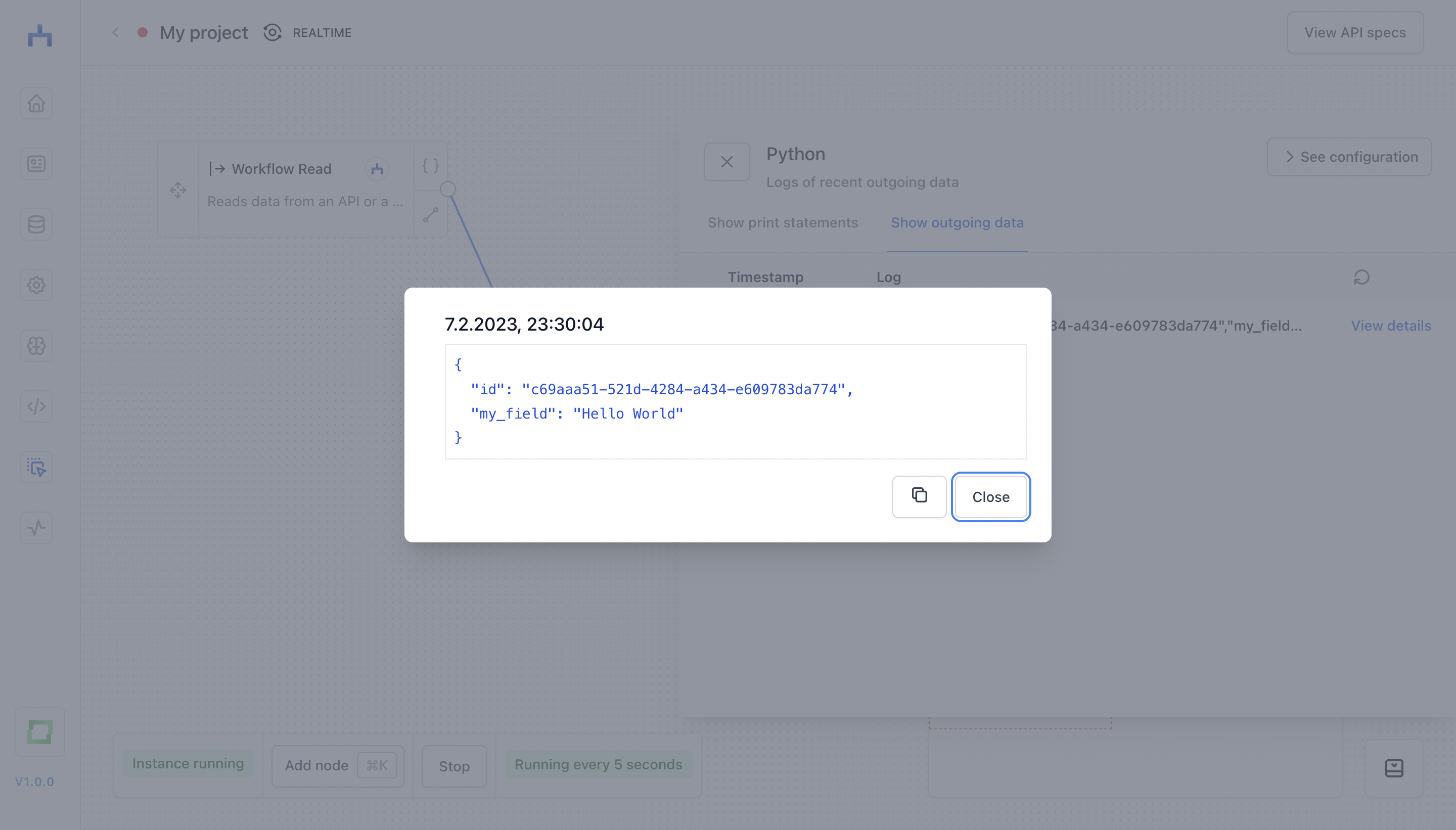
Using environment variables
If you created an environment variable, you can now use it inside of your Python script. For instance, if your variable name is my_variable, you can simply use it in a script with {{ my_variable }}.
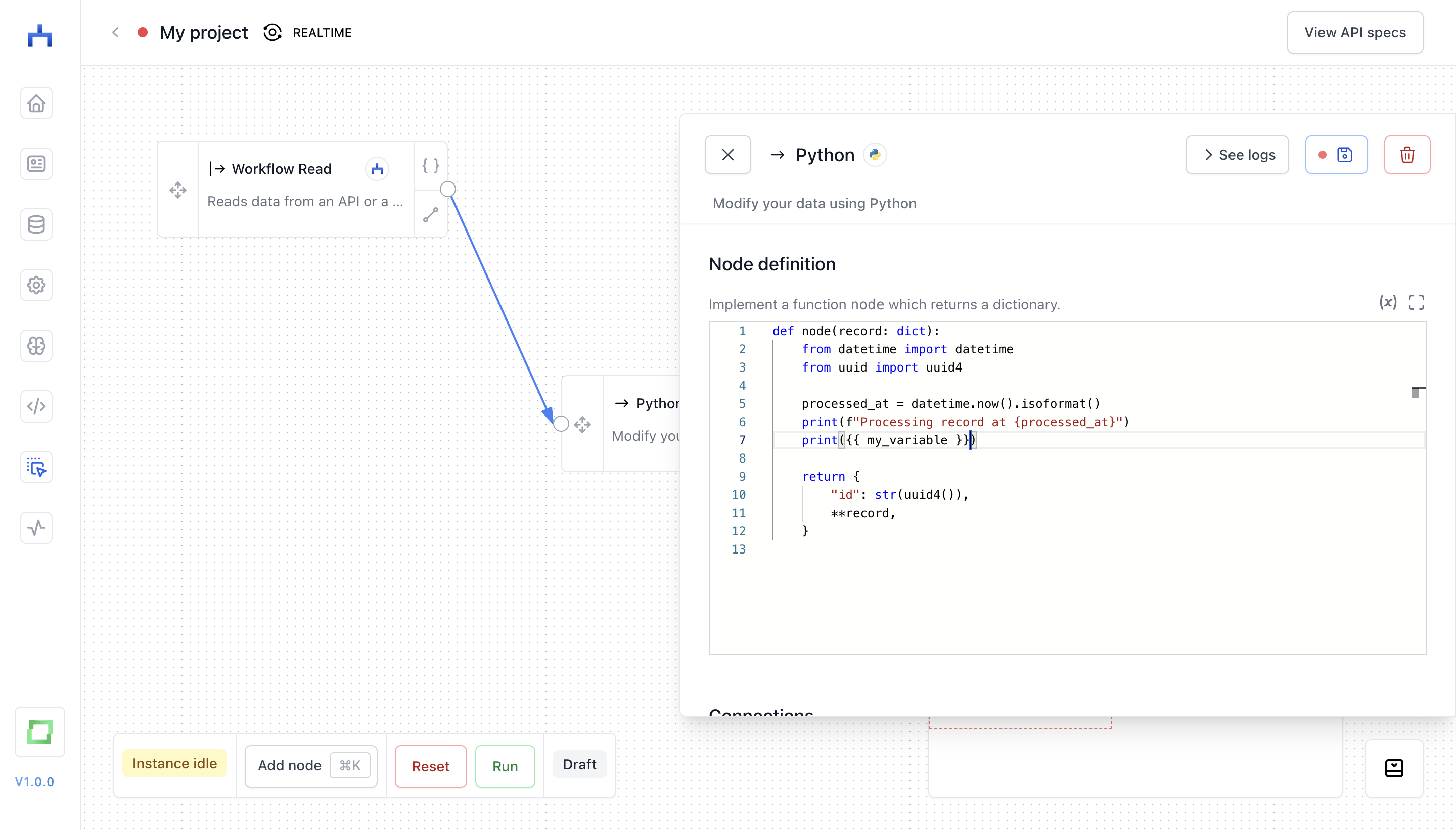
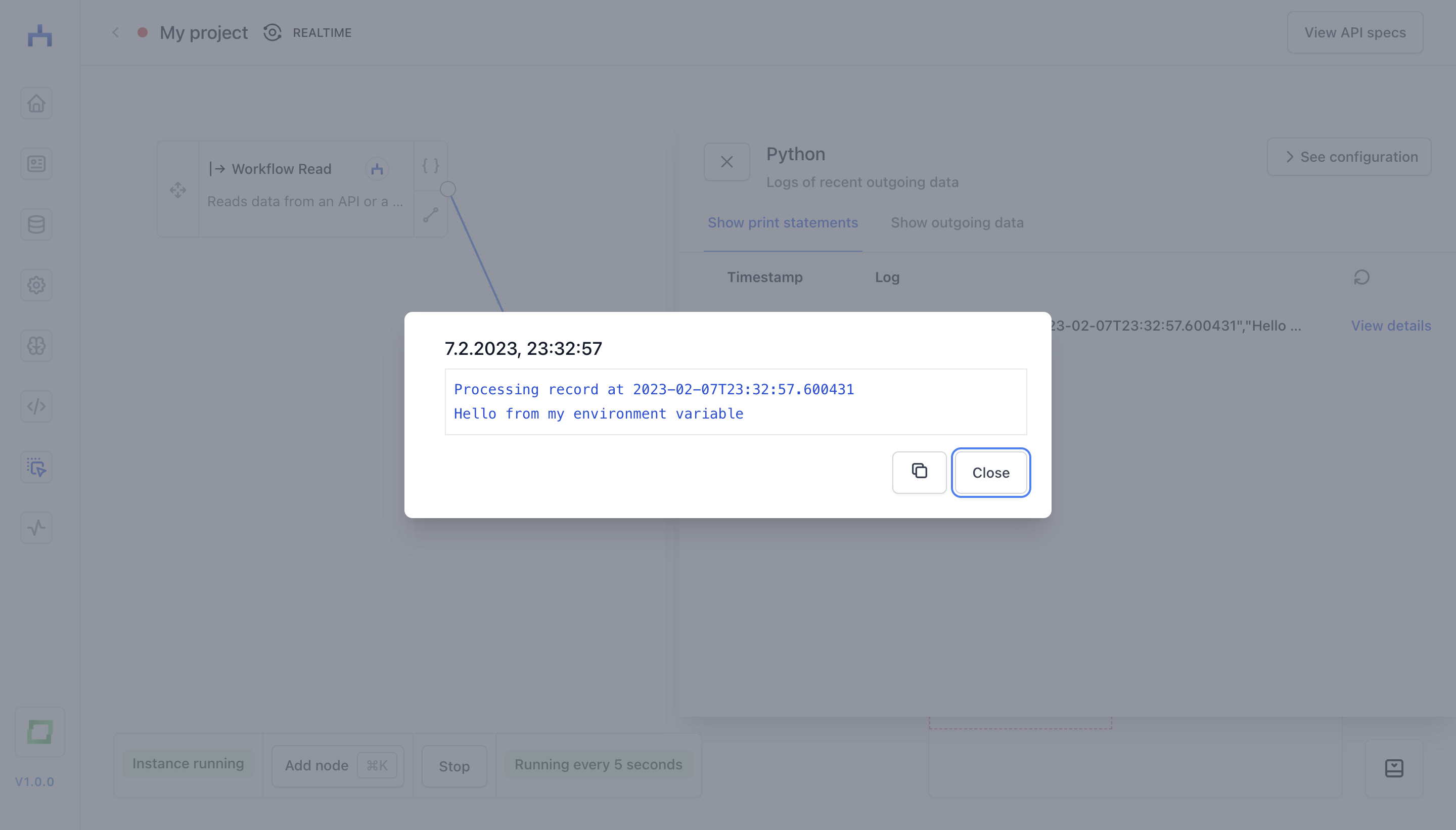
This, in turn, would create the following log (my_variable is "Hello from my environment variable" in this case):
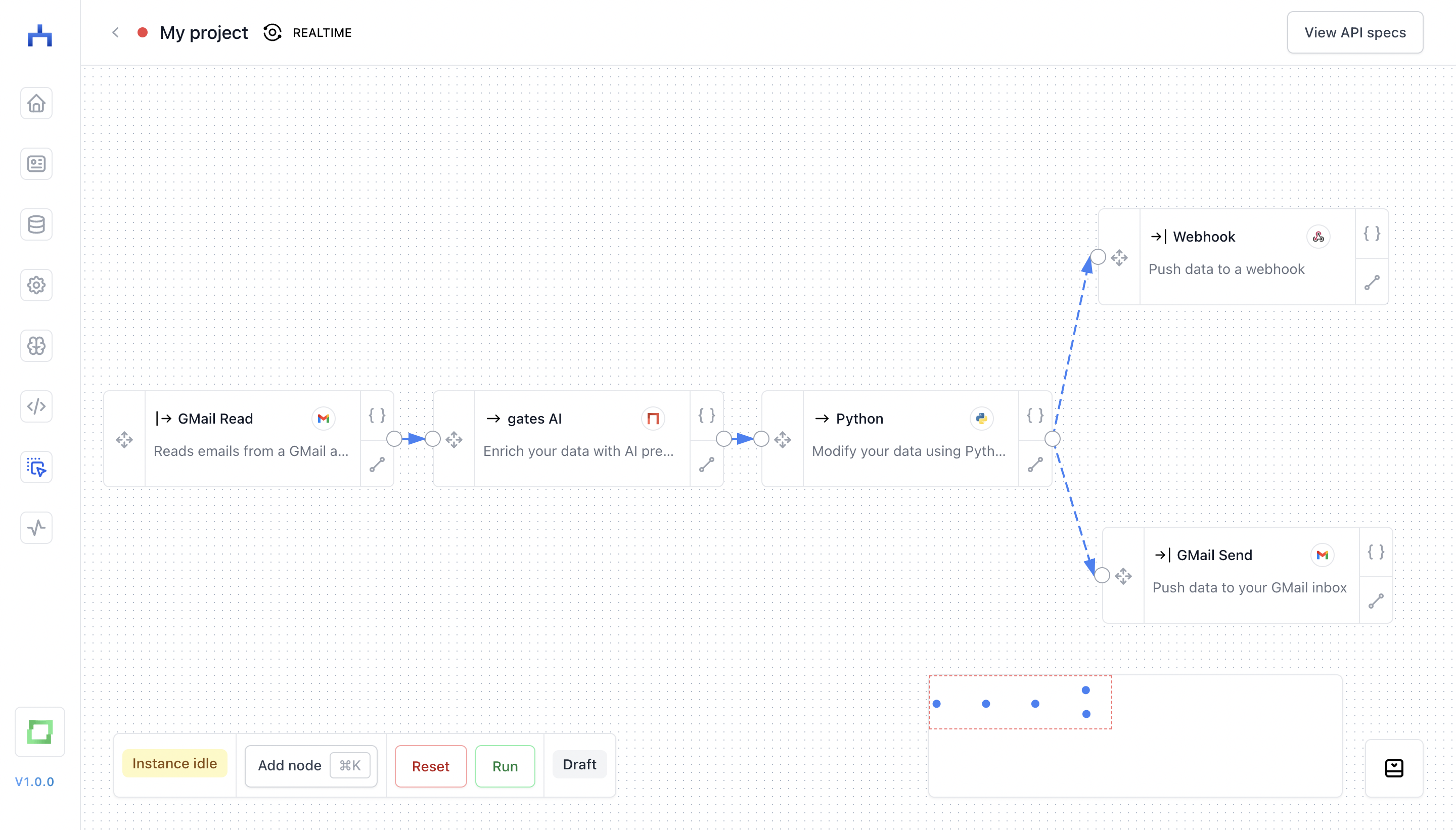
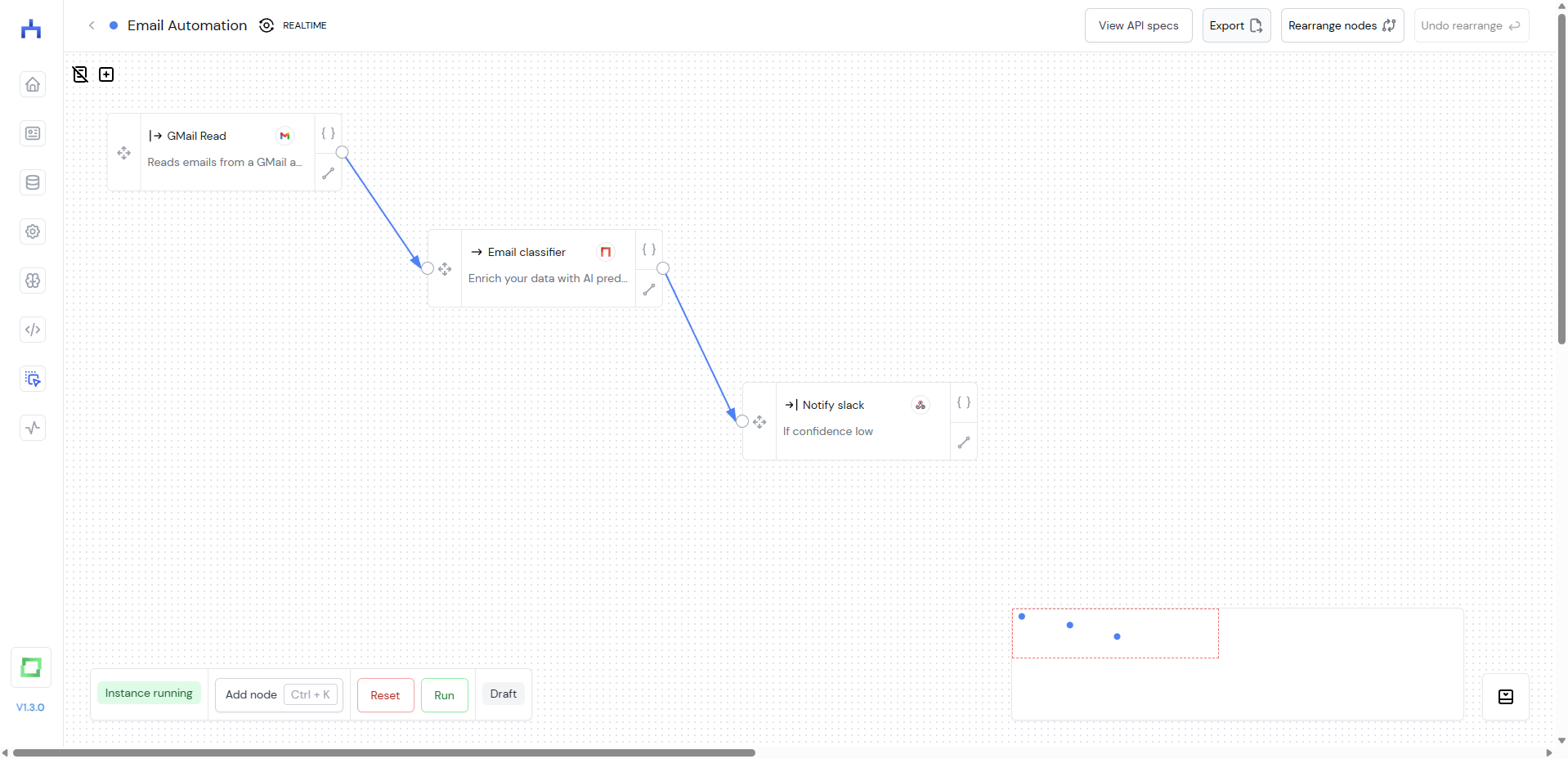
Complex workflows
Ultimately, you can build quite complex workflows with the editor. The following is an example of a workflow that can be read as follows:
- a
sourcenode fetches data from a GMail inbox - each message is enriched via a gates AI node, e.g. to categorize the message or to extract named entities (see more in refinery and gates)
- some postprocessing Python logic, e.g. to flatten the structure of the output
- conditional forwards, e.g. depending on the detected intent or complexity of the message. Either an automated message is sent, or an operator is notified on Slack.
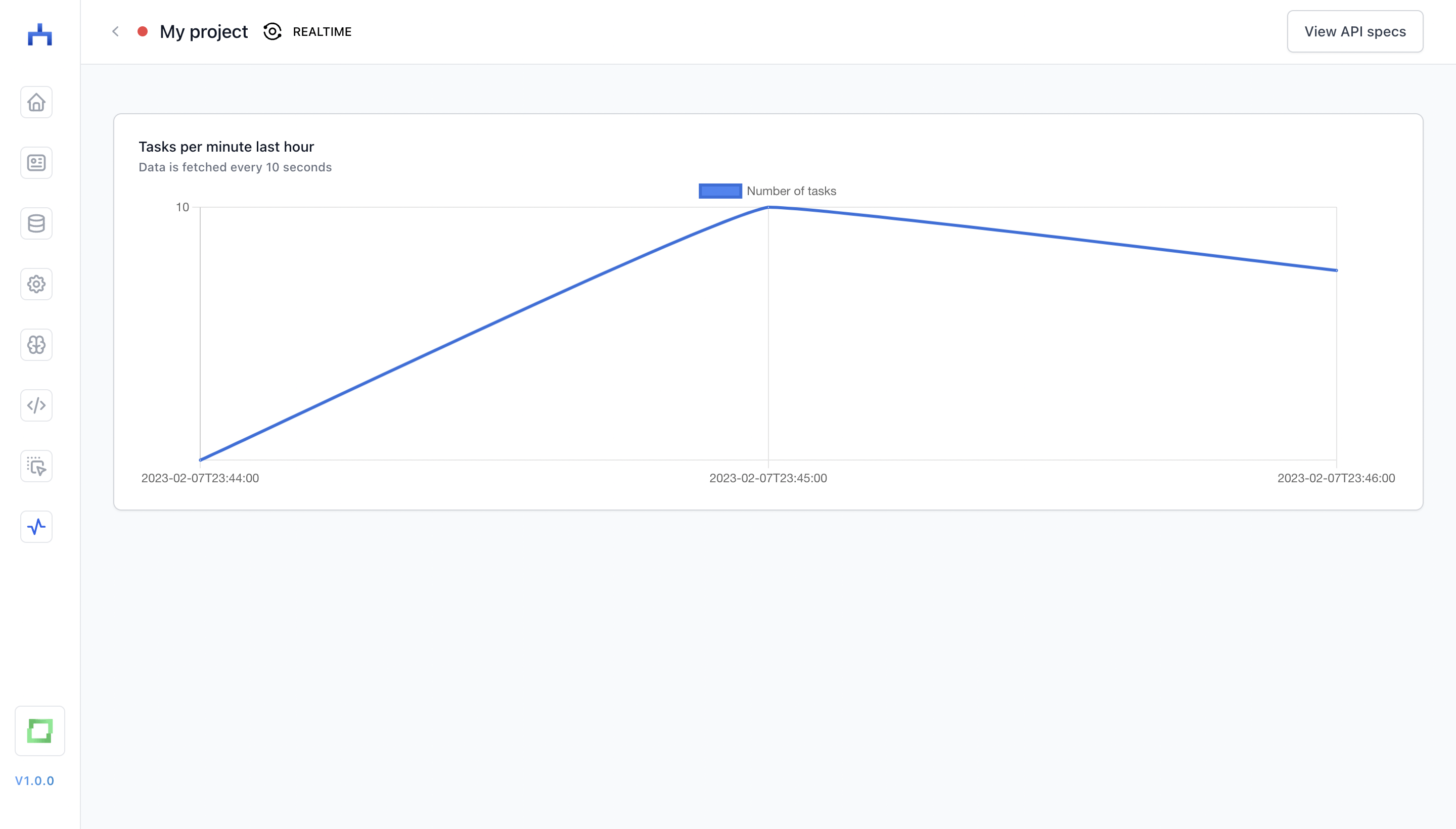
Monitoring workflows
You can monitor the throughput of a workflow on the monitoring page. The throughput is how many tasks have been initiated in a workflow, i.e. as soon as a record has been fetched from a source store, it counts as one task.
Exporting workflows
When entering a project, it is possible to save the workflow locally by clicking the "Export" button on the top right of the page. The workflow project is then downloaded as a .json file.
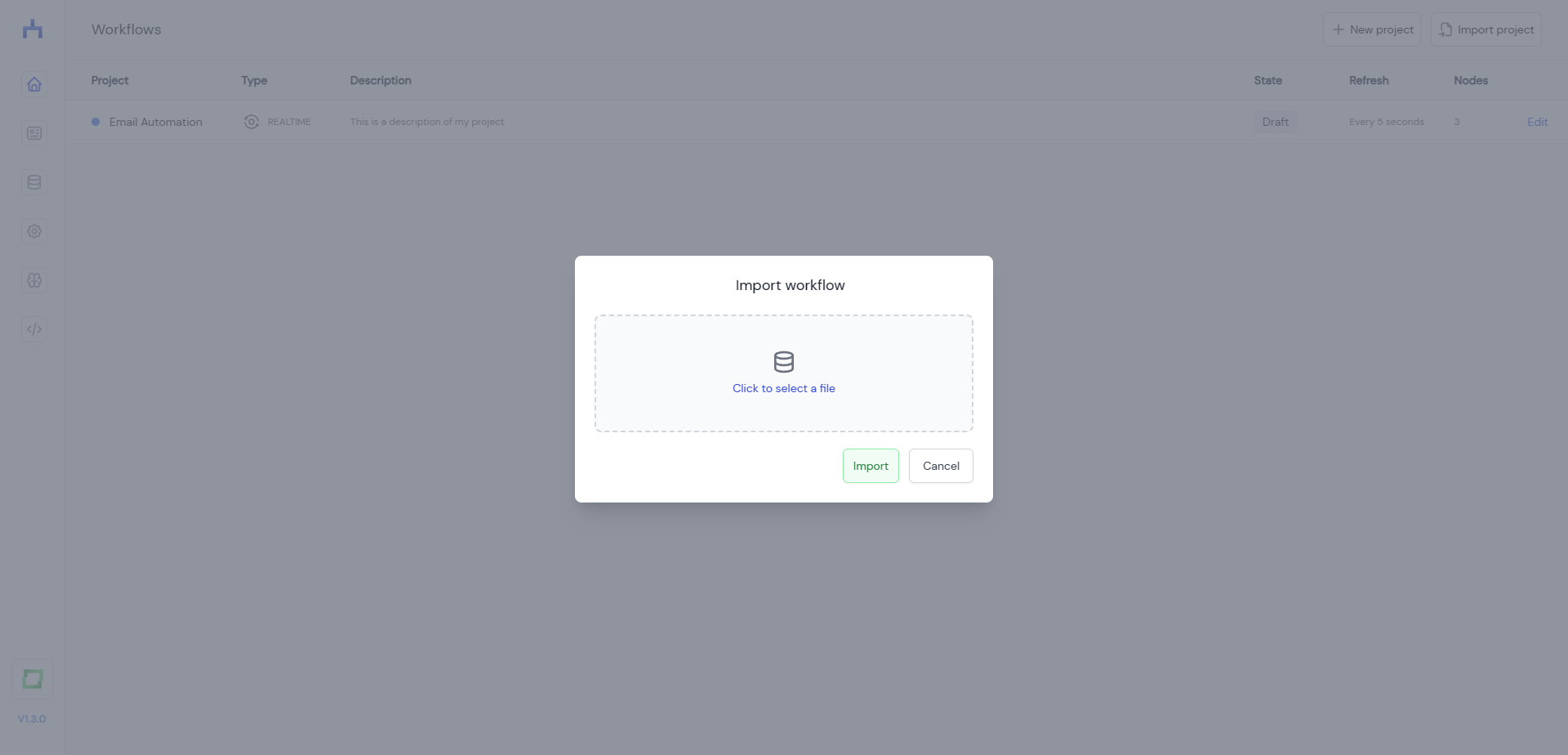
If you want to import a workflow from an existing .json file, navigate to workflow's overview page and click the "Import project" button in the top left.
Workflow API
You can easily retrieve workflows via their unique ID and an access token you create in the application. This is helpful if you want to monitor the throughput of your workflows programmatically.
The workflow model
The store model contains informations such as the name, state, and the nodes.
Properties
- Name
id- Type
- string
- Description
Unique identifier for the workflow.
- Name
organizationId- Type
- string
- Description
Unique identifier of the organization in which the workflow exists.
- Name
name- Type
- string
- Description
The name of the workflow itself.
- Name
description- Type
- string
- Description
The description of the workflow.
- Name
state- Type
- string
- Description
Whether the workflow is currently running or in draft state.
- Name
refreshRateInSeconds- Type
- int
- Description
How many seconds need to pass by until the workflow is triggered again.
- Name
executionType- Type
- string
- Description
Either realtime or batch.
- Name
color- Type
- string
- Description
Color of the dot in the workflow overview page.
- Name
nodes- Type
- list[node]
- Description
List of all nodes in the workflow.
- Name
nodeConnections- Type
- dict
- Description
Dictionary with the conditions for nodes to connect.
- Name
containerIsAvailable- Type
- bool
- Description
Each workflow is running in a containerized environment. If this is
false, it means that the workflow can't be executed.
The node model
The node contains information about the workflowId, its implementation and the conditions between nodes when it was created.
Properties
- Name
id- Type
- string
- Description
Unique identifier for the node.
- Name
organizationId- Type
- string
- Description
Unique identifier of the organization in which the workflow exists.
- Name
name- Type
- string
- Description
The name of the node itself.
- Name
description- Type
- string
- Description
The description of the node.
- Name
category- Type
- string
- Description
Either
sources,modifiersortargets
- Name
code- Type
- string
- Description
Python implementation of the node. For no code nodes, this contains placeholders which are replaced before executing the node.
- Name
isReturnType- Type
- bool
- Description
In most cases, this is
true. It isfalsefor the "Python yield" node, which doesn't use the Pythonreturnkeyword, but instead theyieldkeyword.
- Name
isNoCode- Type
- bool
- Description
If
true, the code attribute contains placeholders that must be replaced before execution.
- Name
noCodeValues- Type
- dict
- Description
Containing the replacements for the placeholders.
- Name
flowDict- Type
- dict
- Description
Containing the condition logic for forwarding data in a workflow.
- Name
positionX- Type
- int
- Description
Relative horizontal position on the canvas.
- Name
positionY- Type
- int
- Description
Relative vertical position on the canvas.
- Name
icon- Type
- string
- Description
Icon identifier for resolving the icon image.
- Name
useCase- Type
- string
- Description
Name of the underlying use case (relevant for templates)
- Name
isTemplate- Type
- bool
- Description
If
true, this node itself can't be executed. It can be replaced with an actual node.
- Name
fromStore- Type
- string
- Description
If a node was initialized from a store, this contains the name of the integration.
- Name
isReady- Type
- bool
- Description
If
true, the node can be executed.
Retrieve a workflow
This endpoint allows you to retrieve a workflow by providing their id. Refer to the list at the top of this page to see which properties are included with workflow objects.
Request
curl https://app.kern.ai/workflow-api/workflows/WAz8eIbvDR60rouK \
-H "Authorization: {token}"
Response
{
"id": "f5820b73-0a07-4551-b2f3-31486a124188",
"organizationId": "8502b0fb-cfaf-45ce-b0a7-71231cb8e769",
"name": "My project",
"description": "This is a description of my project",
"state": "RUNNING",
"refreshRateInSeconds": 5,
"executionType": "REALTIME",
"color": "bg-red-500",
"nodes": [{
"id": "380c8c39-c333-4e41-8d40-adb63972f826", "
organizationId": "8502b0fb-cfaf-45ce-b0a7-71231cb8e769",
"workflowId": "f5820b73-0a07-4551-b2f3-31486a124188",
"name": "Auto Trigger",
"description": "Emits a timestamp trigger",
"category": "sources",
"code": "def node() -> dict:\n import time\n\n return {\n "unix_timestamp": time.time(),\n }\n",
"isReturnType": True,
"isAggregatorType": False,
"isNoCode": True,
"noCodeValues": {},
"flowDict": {
"5057c850-31e4-4f64-825f-e2ad5774fff3": "True",
"cc79a21f-c36a-4f8e-887c-07bf0cc2f131": "False"
},
"positionX": 75,
"positionY": 75,
"icon": "CRON",
"useCase": "Auto Trigger",
"isTemplate": False,
"fromStore": None,
"isReady": True
}, {
"id": "5057c850-31e4-4f64-825f-e2ad5774fff3",
"organizationId": "8502b0fb-cfaf-45ce-b0a7-71231cb8e769",
"workflowId": "f5820b73-0a07-4551-b2f3-31486a124188",
"name": "Python",
"description": "Modify your data using Python",
"category": "modifiers",
"code": "def node(record: dict):\n from datetime import datetime\n from uuid import uuid4\n\n processed_at = datetime.now().isoformat()\n print(f"Processing record at {processed_at}")\n\n return {\n "id": str(uuid4()),\n **record,\n }\n",
"isReturnType": True,
"isAggregatorType": False,
"isNoCode": False,
"noCodeValues": {},
"flowDict": {
"380c8c39-c333-4e41-8d40-adb63972f826": "False",
"cc79a21f-c36a-4f8e-887c-07bf0cc2f131": "True"
},
"positionX": 150,
"positionY": 202,
"icon": "python",
"useCase": None,
"isTemplate": False,
"fromStore": None,
"isReady": True
}, {
"id": "cc79a21f-c36a-4f8e-887c-07bf0cc2f131",
"organizationId": "8502b0fb-cfaf-45ce-b0a7-71231cb8e769",
"workflowId": "f5820b73-0a07-4551-b2f3-31486a124188",
"name": "Shared Store Send",
"description": "Send data to a shared store",
"category": "targets",
"code": "def node(record):\n import requests\n\n response = requests.post(\n url="http://workflow-engine:80/stores/@@PLACEHOLDER_MART_ID@@/create-entry-from-node",\n headers={"Content-Type": "application/json"},\n json={\n "nodeId": "@@PLACEHOLDER_NODE_ID@@",\n "data": record,\n }, # you might need to change this to the format of the webhook\n )\n if response.status_code == 200:\n data = response.json()\n print(f"Sending {data} to store")\n",
"isReturnType": True,
"isAggregatorType": False,
"isNoCode": True,
"noCodeValues": {
"PLACEHOLDER_MART_ID": "a6d7530f-257f-44cc-a575-f2371c54193e",
"PLACEHOLDER_DATETIME": "2000-01-01T00:00",
"PLACEHOLDER_EMISSION_TYPE": "record"
}, "flowDict": {
"380c8c39-c333-4e41-8d40-adb63972f826": "False",
"5057c850-31e4-4f64-825f-e2ad5774fff3": "False"
},
"positionX": 232,
"positionY": 337,
"icon": "workflow",
"useCase": None,
"isTemplate": False,
"fromStore": "Shared Store Send",
"isReady": True
}],
"nodeConnections": {
"380c8c39-c333-4e41-8d40-adb63972f826": [],
"5057c850-31e4-4f64-825f-e2ad5774fff3": ["380c8c39-c333-4e41-8d40-adb63972f826"],
"cc79a21f-c36a-4f8e-887c-07bf0cc2f131": ["380c8c39-c333-4e41-8d40-adb63972f826", "5057c850-31e4-4f64-825f-e2ad5774fff3"]
},
"containerIsAvailable": True
}
Get the throughput
This endpoint allows you to retrieve the throughput of a workflow as a simple list.
Request
curl -X DELETE https://app.kern.ai/workflow-api/workflows/WAz8eIbvDR60rouK/throughput \
-H "Authorization: {token}"
Response
[{
"timestampMinute": "2023-02-13T20:27:00", "numTasks": 5
}, {
"timestampMinute": "2023-02-13T20:28:00", "numTasks": 4
}]