
Neural search
Neural search refers to the concept of search in an embedding space that is created by neural networks. Instead of searching for co-occurring n-grams to retrieve similar records, neural search uses the context-rich embeddings generated by large pre-trained language models and a distance metric in that space to define similarity between records. This similarity can be used for both use cases: for finding similar data, but also for detecting outliers.
One pre-requisite to using neural search is that you already added embeddings to the project.
Similarity search
Every record in the data browser has the option to "find similar records" which will calculate the cosine similarity using the selected embeddings. After selecting the embedding, the data browser then displays records with descending similarity starting from the record that you requested the similarity search for (as it is the most similar to itself).
When using similarity search you cannot filter for anything else. Doing so will replace the similarity search. Similarity search cannot be saved as a data slice.
Outlier detection
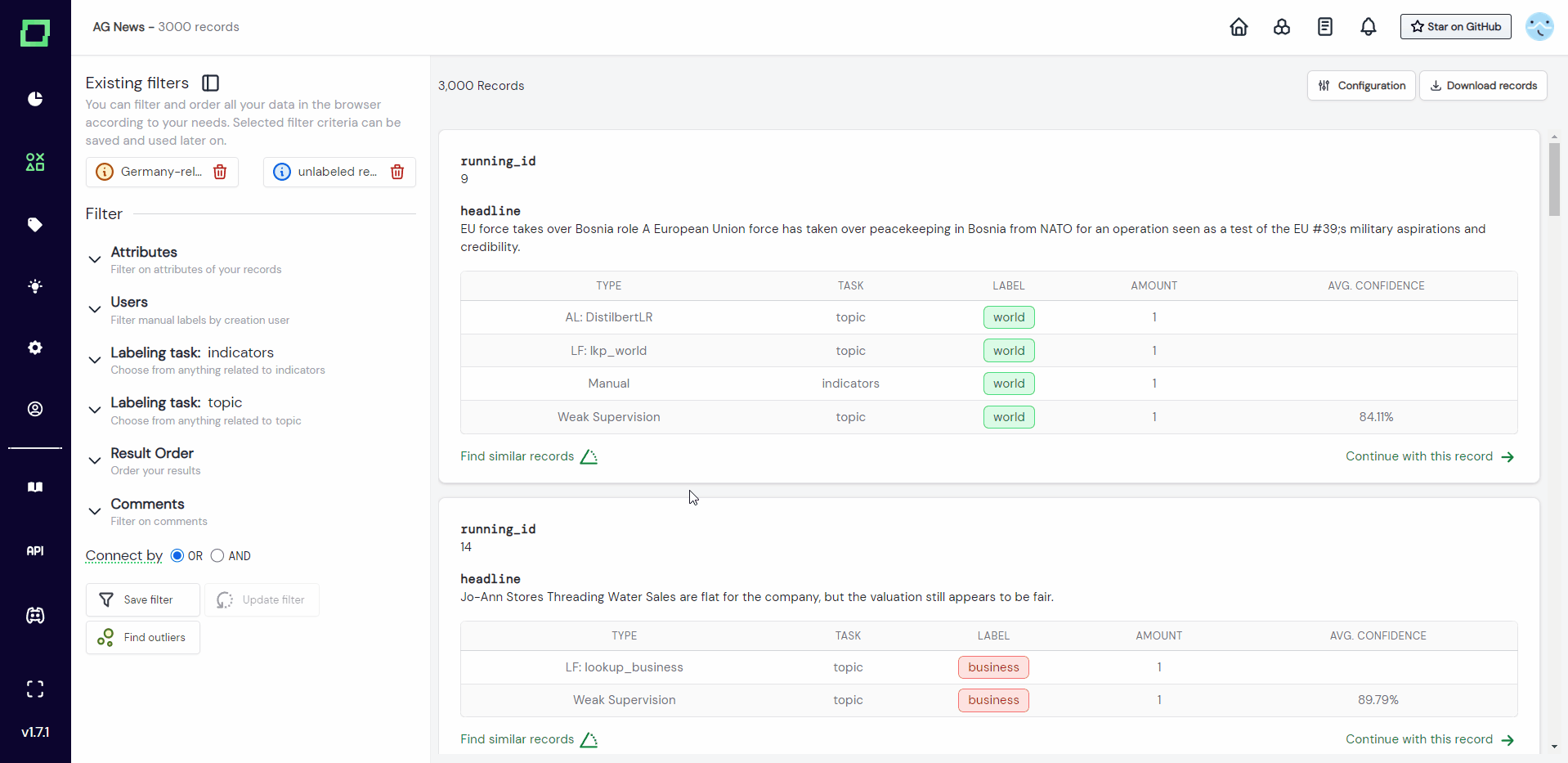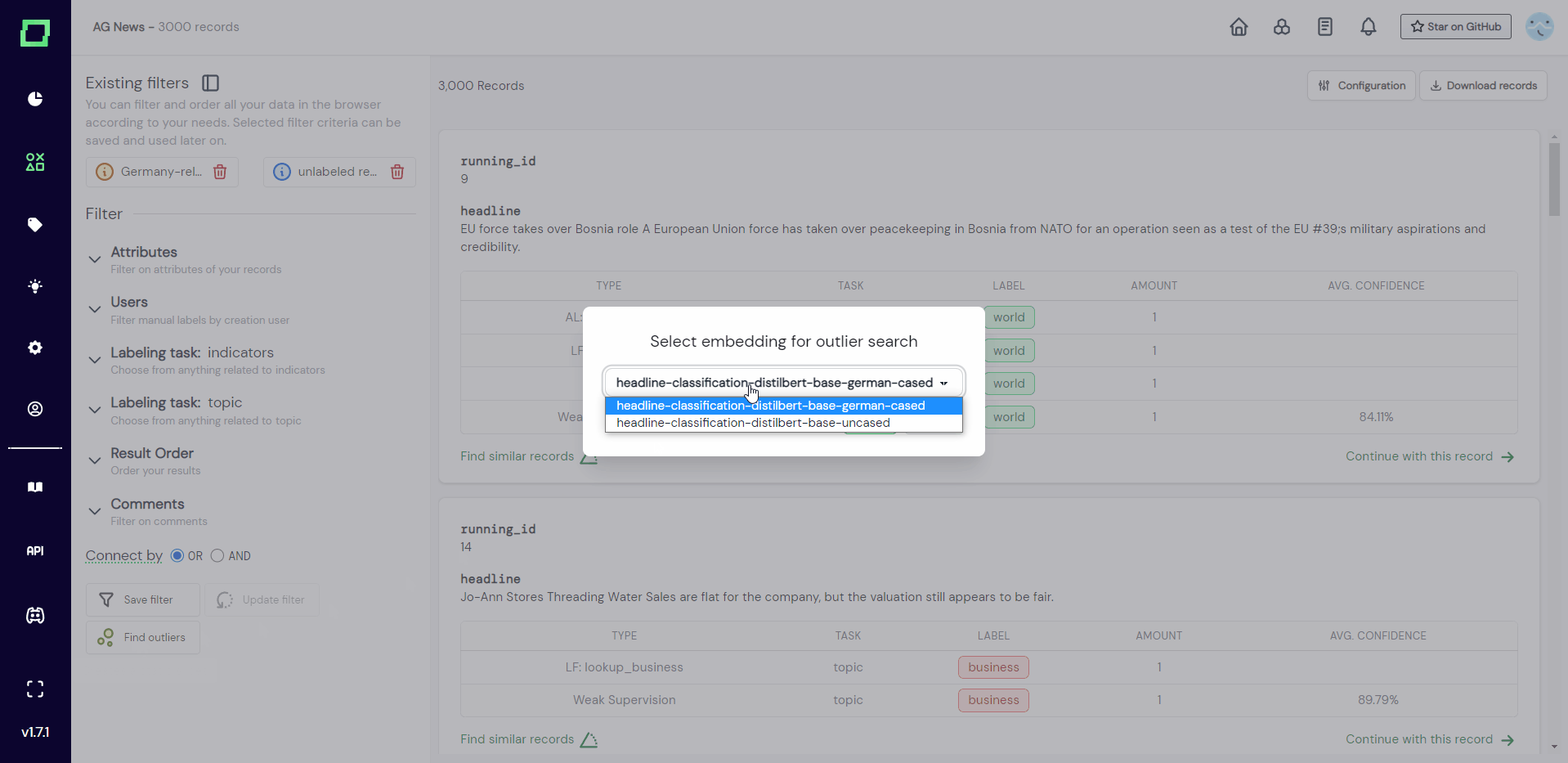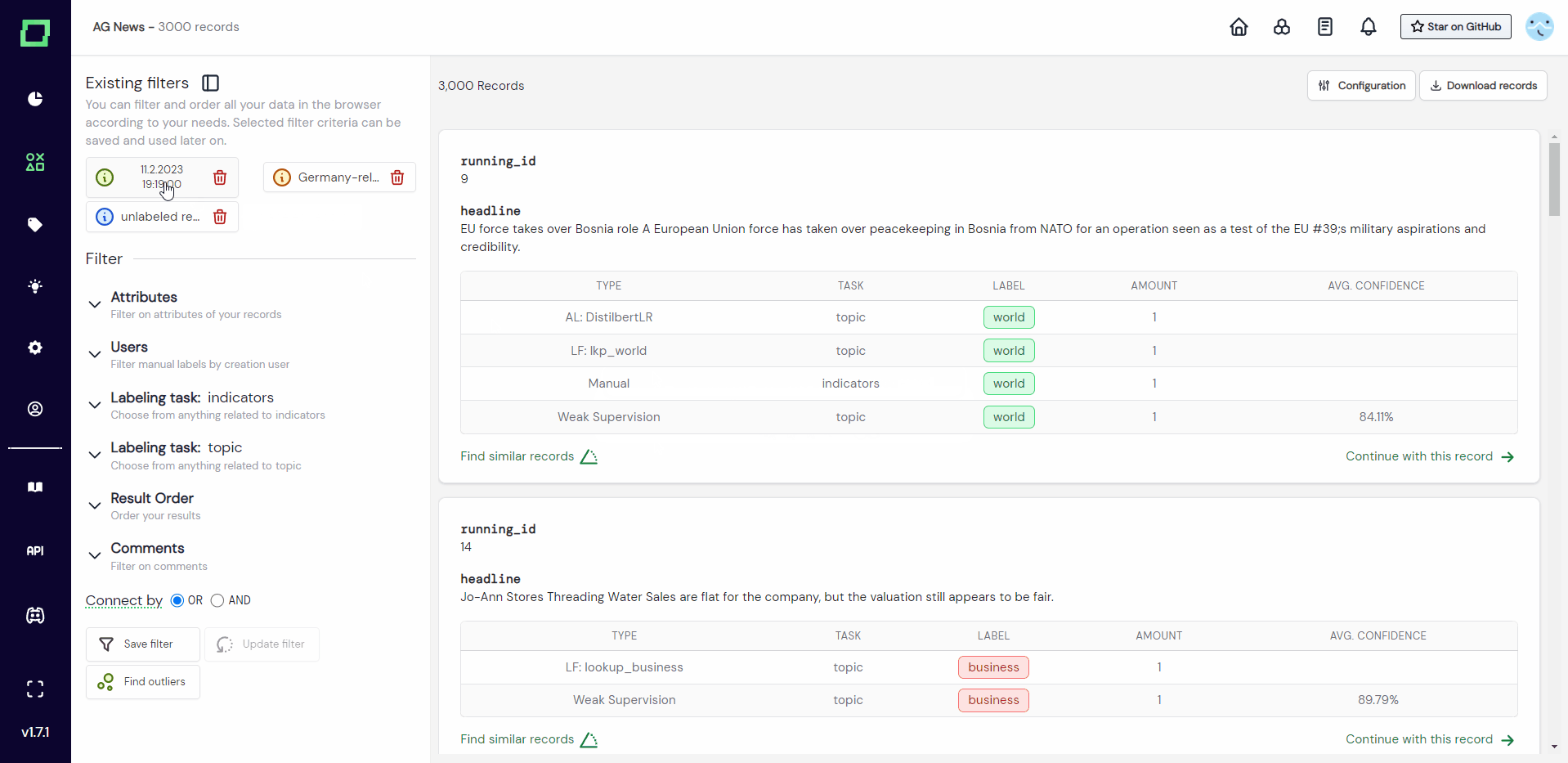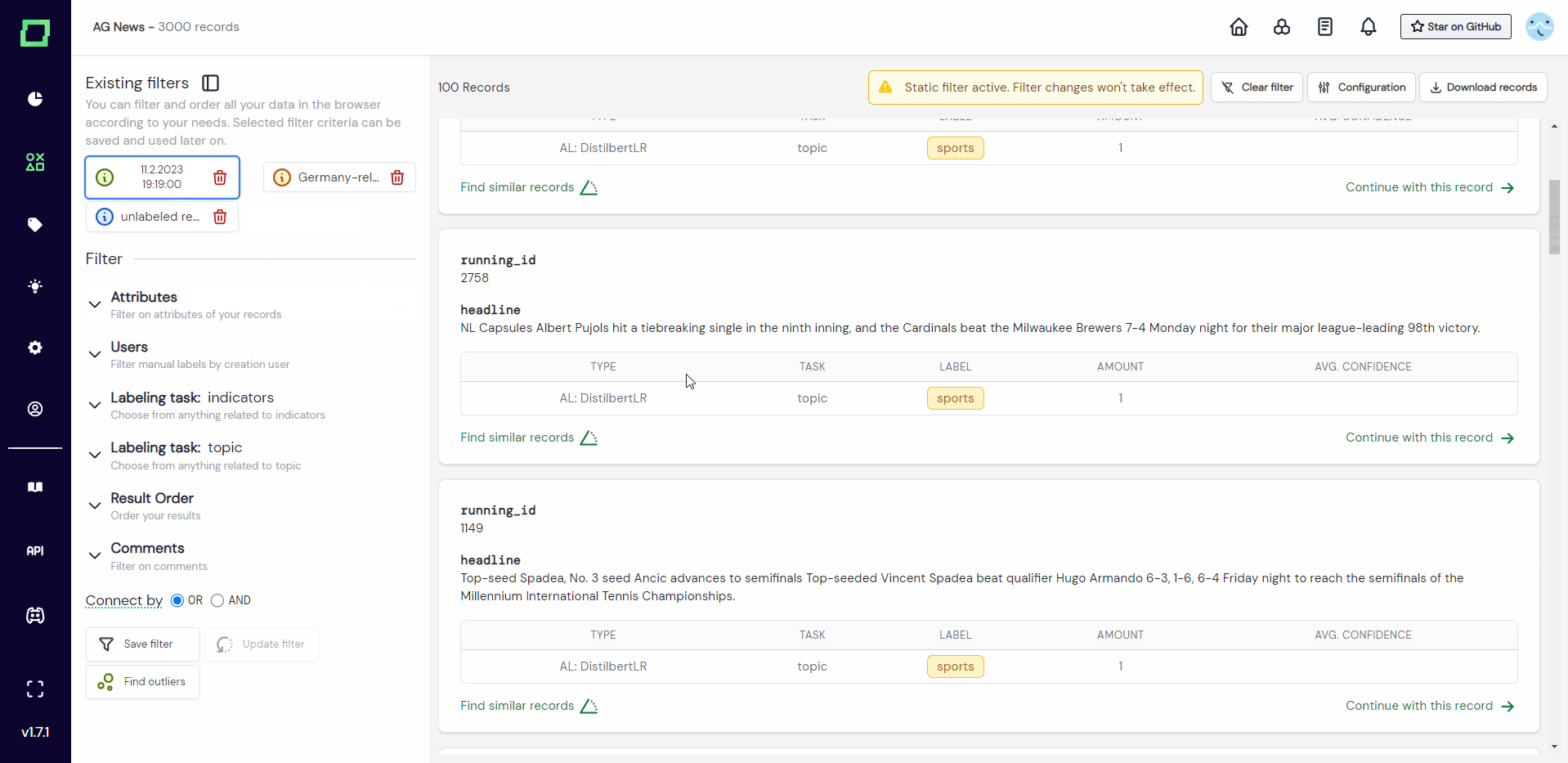
We make use of vector distance comparison to find records that are - given some vector space - most likely outliers. To use this feature, we need at least one labeled record, as we compare pools of unlabeled and labeled data for this outlier detection (even though to really make sense you should have labeled more).
The outlier detection will create a data slice containing 100 records that are (on average) the most different (or least similar) from the already labeled data. The similarity will be measured by cosine distance in the embedding space. This data slice will be ordered by ascending similarity.
This feature is accessible at the very bottom of the data browser filter sidebar. Just click on the "Find outliers" button there.
The results of the outlier detection are heavily dependent on the vector space. Especially when used as a filter criterium for the monitoring page, you can quickly find weak spots or/and obstacles in your data, e.g. detect faulty records or completely unrelated languages.