
Classifiers
Classifiers are the modules that summarise a text into a specific category for example classify a set of news records into “politics” and “business”.
Apart from that, the modules concerning enrichments like language detection are also put into classifiers. The available classifiers can be viewed as a collection as shown below.
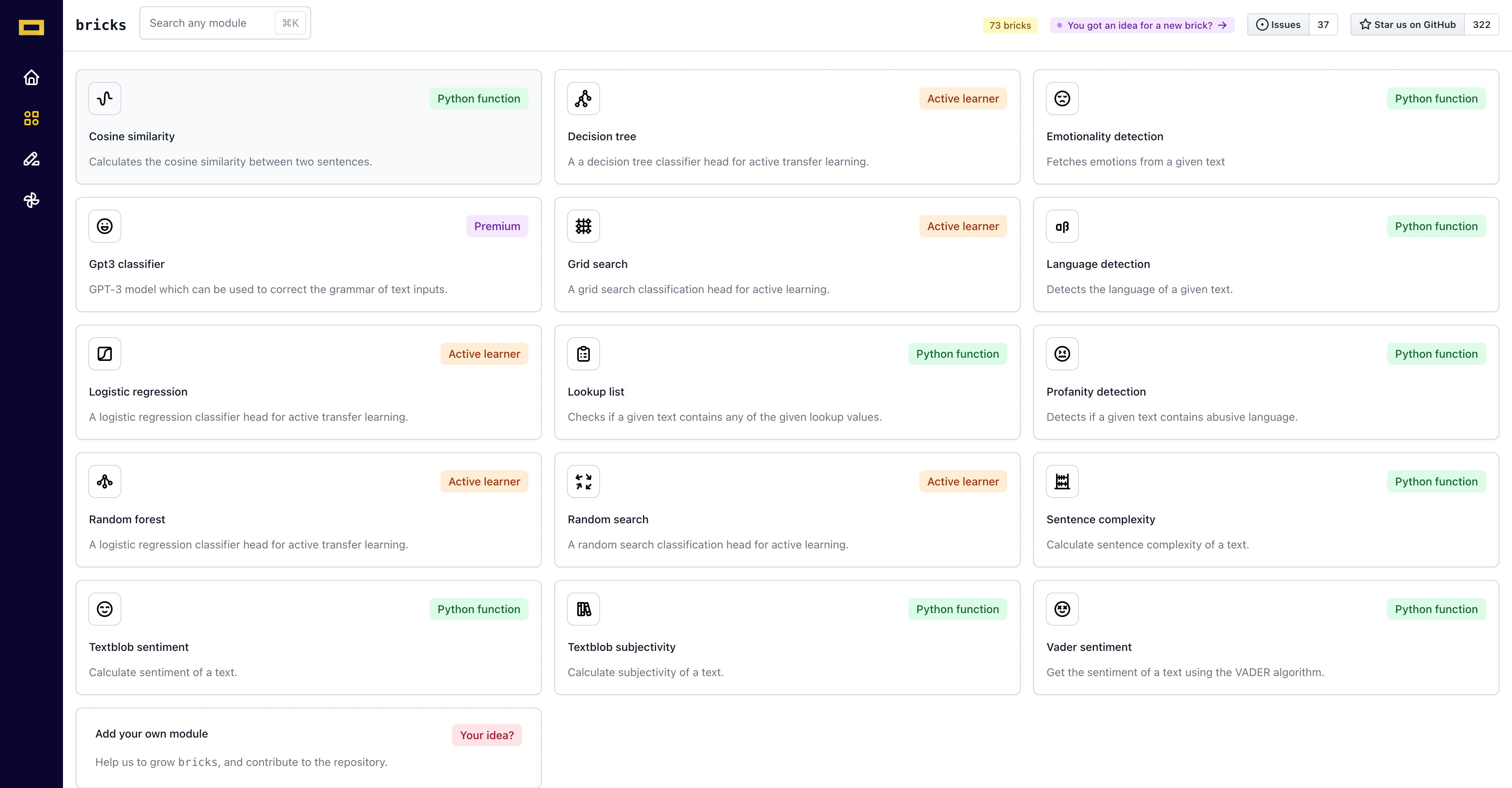
As you can see, the classifiers are sub-categorised according to their execution types - “Python function”, “Premium” and “Active learner”. More information is provided on this in the later part of this documentation (see execution types).
Let us go through an example of the “language detection” classifier. You can navigate to the module page by clicking Language detection .
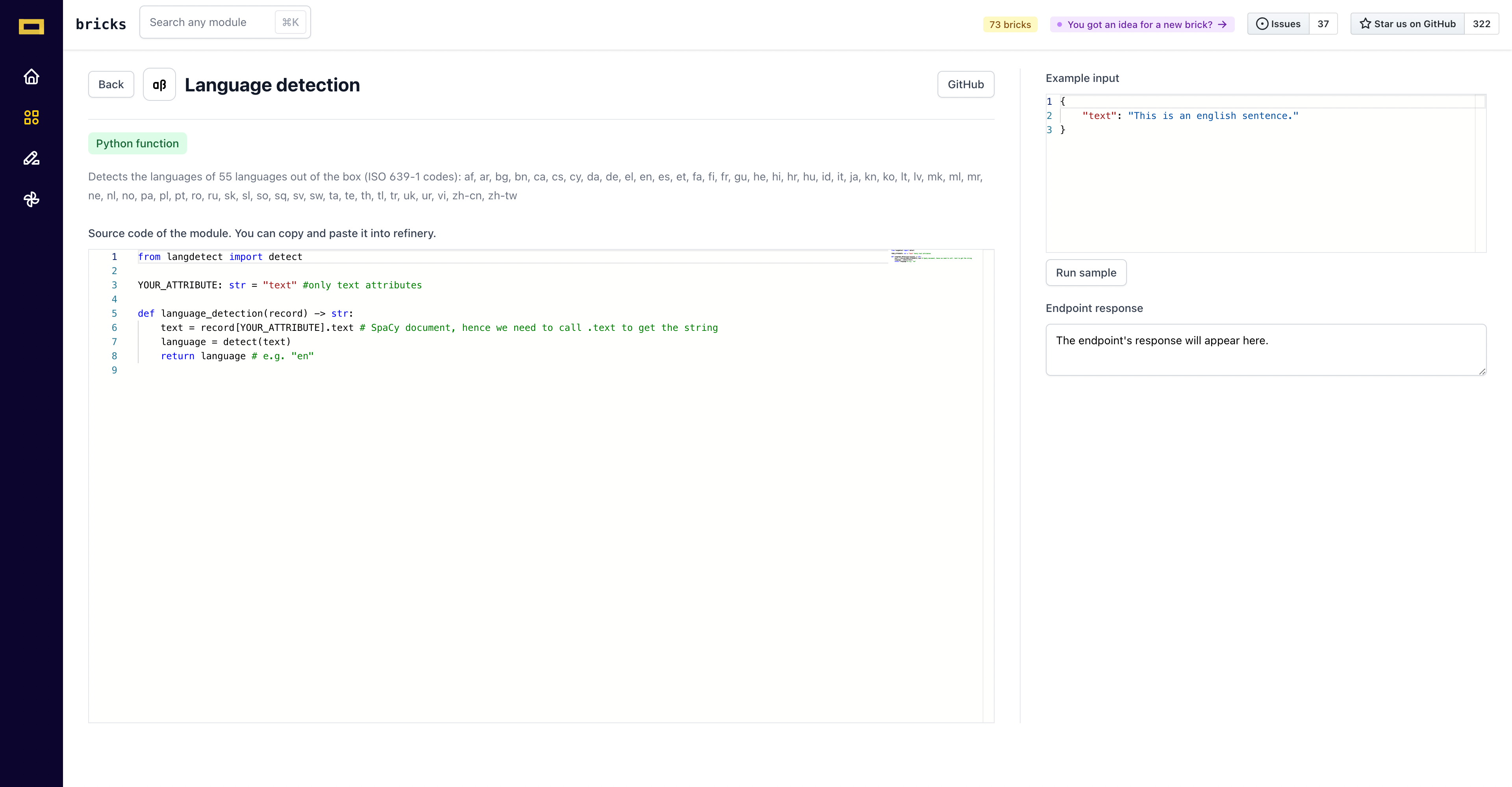
The module page shows the code snippet meant to detect languages. This code snippet field is non-editable, you can only copy-paste the code into refinery.
On the right side of the page, you can find an input field with a default input text. This input can be modified by you if you want to test the module over multiple texts.
When you click on Run sample , the output is generated in the form of a dictionary.
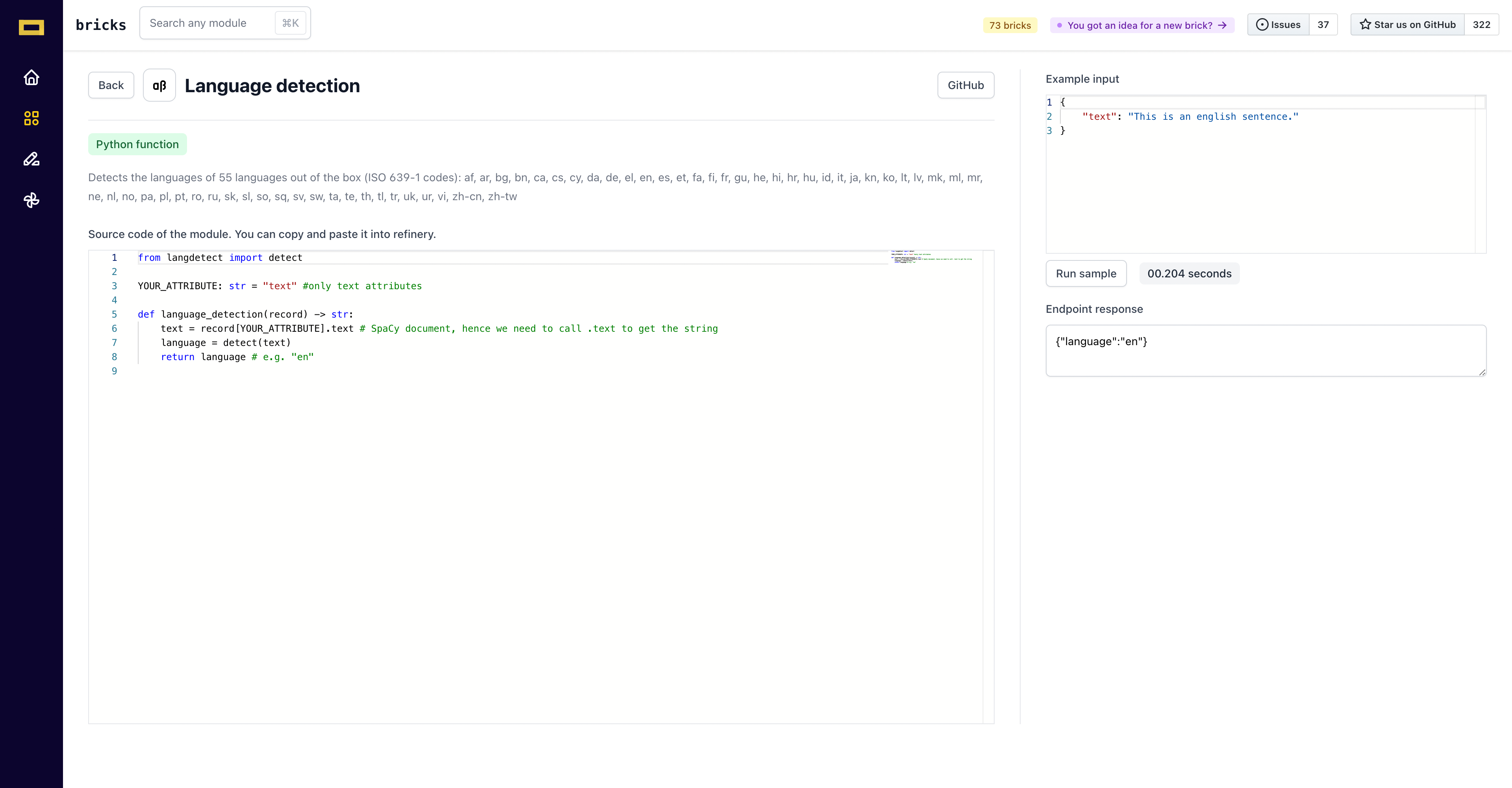
And done! You can see, in this case, what language your text is in. In refinery, you can create a new attribute or a new heuristic and import the classifier module using the bricks integration feature which is an upgrade of simply copy-pasting the code snippet in refinery manually.
The GitHub button in front of the module name redirects you to the issue
page where, in case of malfunction, you can re-open the issue, or open a new
issue if you come up with a new idea for a classifier.