
Evaluating heuristics
Evaluating your heuristics is key in making informed decisions on their inclusion or exclusion during weak supervision. Even though there are other indicators of heuristic quality, the most important one is the estimated accuracy, which gets more and more accurate the more manually labeled reference data you have. So before committing fully to evaluating your heuristics, first make sure to provide enough manually labeled data!
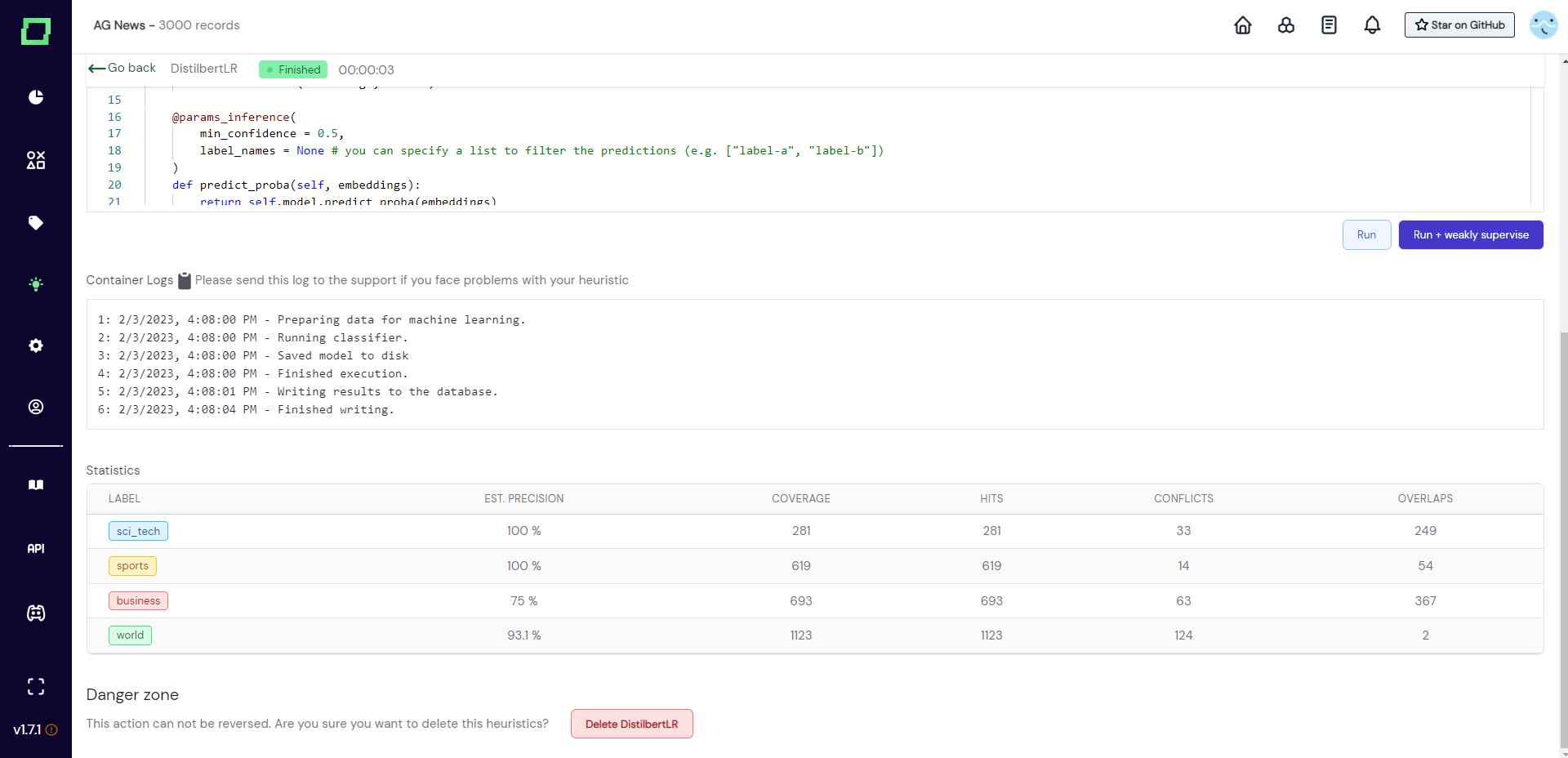
Statistics
Refinery constantly keeps track of how well your heuristics are doing, no matter what type they are. Once you execute a heuristic - and there is some manually labeled data we can use for evaluation - you will find the following statistic at the bottom of your heuristic details page:
- Est. precision: estimated precision on the manually labeled reference data (records that have the same label as the heuristic is assigning). Calculated with
true positives / (true positives + false positives). Gets more precise the more reference data you label. - Coverage: Number of records that this heuristic makes a prediction for.
- Hits: Number of spans that this heuristic makes a prediction for. This will always be the same number as coverage for classification tasks but could differ for extraction tasks as they could have multiple spans labeled for a single record.
- Conflicts: Number of instances (record or span) where this heuristics's prediction is different from other heuristic's predictions. Is by definition smaller or equal to overlaps.
- Overlaps: Number of instances (record or span) where this heuristic makes a prediction and at least one other heuristic also makes a prediction.
Updating interval
As statics are crucial to the estimation of heuristic quality, refinery updates them automatically and the user must not re-run them all the time. Because updating the statistics after every manual label would be computationally expensive, we opted for a debounce time. This means that after you labeled a little bit of data and have not set any new label for a few seconds, refinery triggers a re-run of the statistics calculation in the background. That means they will not be available immediately but will reach consistency eventually (just a few seconds usually).
Best practices
When working with heuristics in refinery, you develop certain patterns of evaluation that can be regarded as best practices. We want to share a few of those here and will constantly expand this section.
Random labeling
We know this does not sound exciting, but one of the best (unbiased) ways of validating your heuristics is to label data randomly. Just go into the data browser, select the manual label filter option "has no label" for your respective labeling task, go to the result order and select "random". Either save this a dynamic data slice or just jump into the labeling session.
Validation slices
One common way to precisely validate a single heuristic is to create a dynamic data slice with two criteria:
- no manual label
- heuristic makes a prediction
This data slice will always contain data that is relevant to give a better precision estimate as you provide more manually labeled reference data for the statistics. Usually, labeling 15-30 records directly after creating the heuristic already gives a good estimate.