

refinery
This is the official documentation of refinery - the data scientist's open-source tool of choice to scale, assess and maintain natural language data.
Flagship product of Kern AI
As you can tell from this documentation - refinery is our flagship product. It is incredibly powerful, and can help you build strong NLP.
In the documentation, you will see screenshots of refinery with the actual Kern AI brand logo. Don't get confused by this, until recently, refinery's and Kern AI's logo was the same. We just recently gave refinery a full standalone logo :)
Structure of this documentation
The documentation is structured by features of refinery. You can start via the following quickstart!
Features of refinery
refinery comes with the following features.
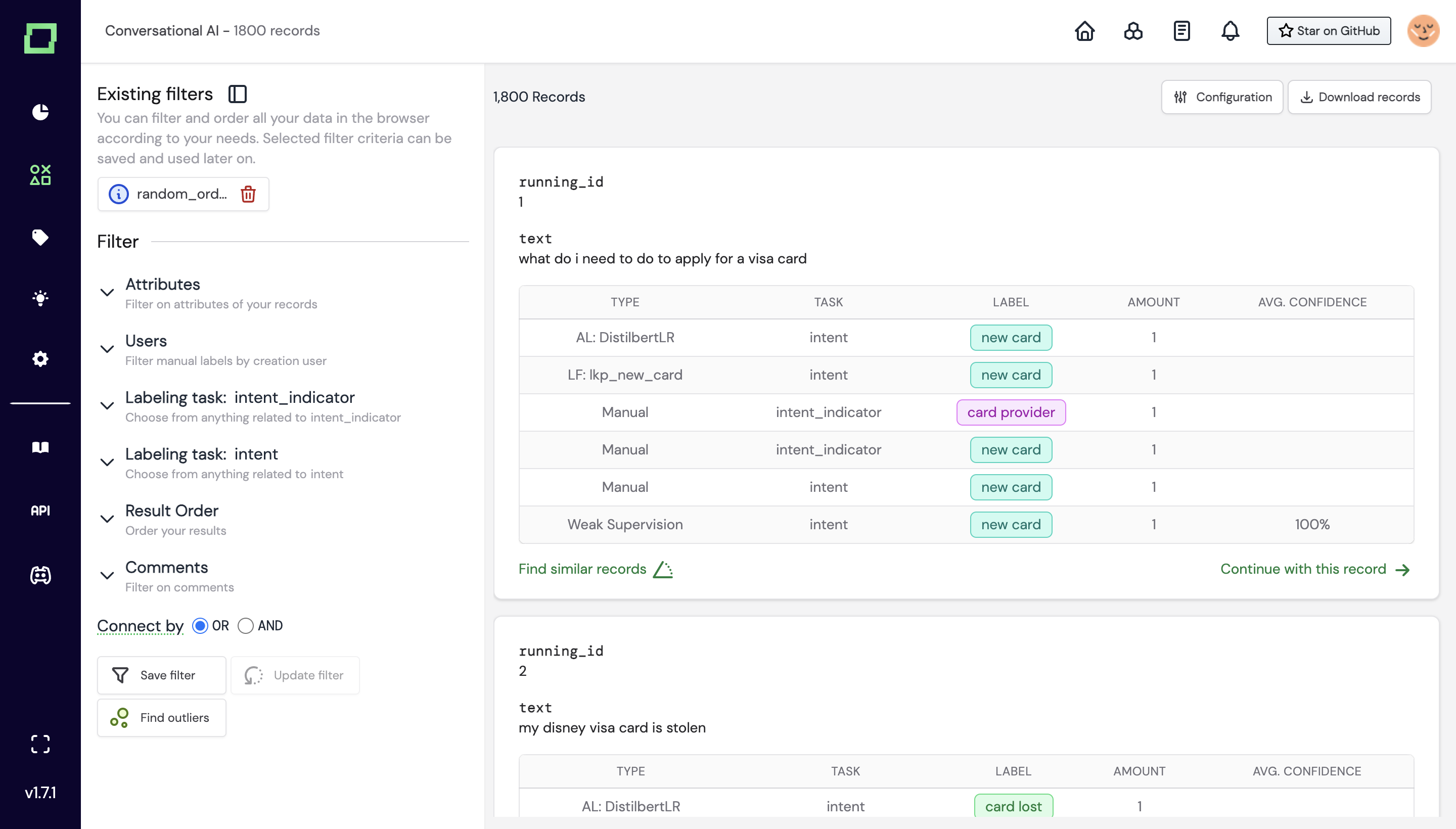
Manual labeling editor
refinery comes with a built-in editor (incl. role-based access) supporting classifications, span-extraction and text generation. Further, you can export data to other annotation tools like Labelstudio.
Best-in-class data management
Use our modular data management to find e.g. records with below 30% confidence and mismatching manual and automated labels, sorted by confidence. Assign that data either to an inhouse expert or a crowdlabeler.
Native large-language-model integration and finetuning
You love Hugging Face, GPT-X or cohere for their large language models? We do too. That is why we integrated them into refinery. You can use them for embeddings (and neural search), active transfer learning, or even to create the training data for finetuning these LLMs on your data.
Automate with heuristics
refinery is shipped with a Monaco editor, enabling you to write heuristics in plain Python. Use them for e.g. rules, API calls, regex, active transfer learning or zero-shot predictions
Monitor your data quality
In the project dashboard, you can find distribution statistics and a confusion matrix showing you where your project needs improvement. Every analysis can be filtered down to atomic level.
Open-source
Yes, you read that right. Our flagship product is open-sourced under the Apache 2.0 license. You can find the code on GitHub. We are also happy to accept contributions.