
Extractors
These are the modules that extract some specific information from a given text.
The extractors bring along a lot of use-cases with them, like extracting addresses from a given text, or extracting date and time values from a text.
Let us go through an example of using the hashtag extraction which can be accessed by clicking the Hashtag extraction .
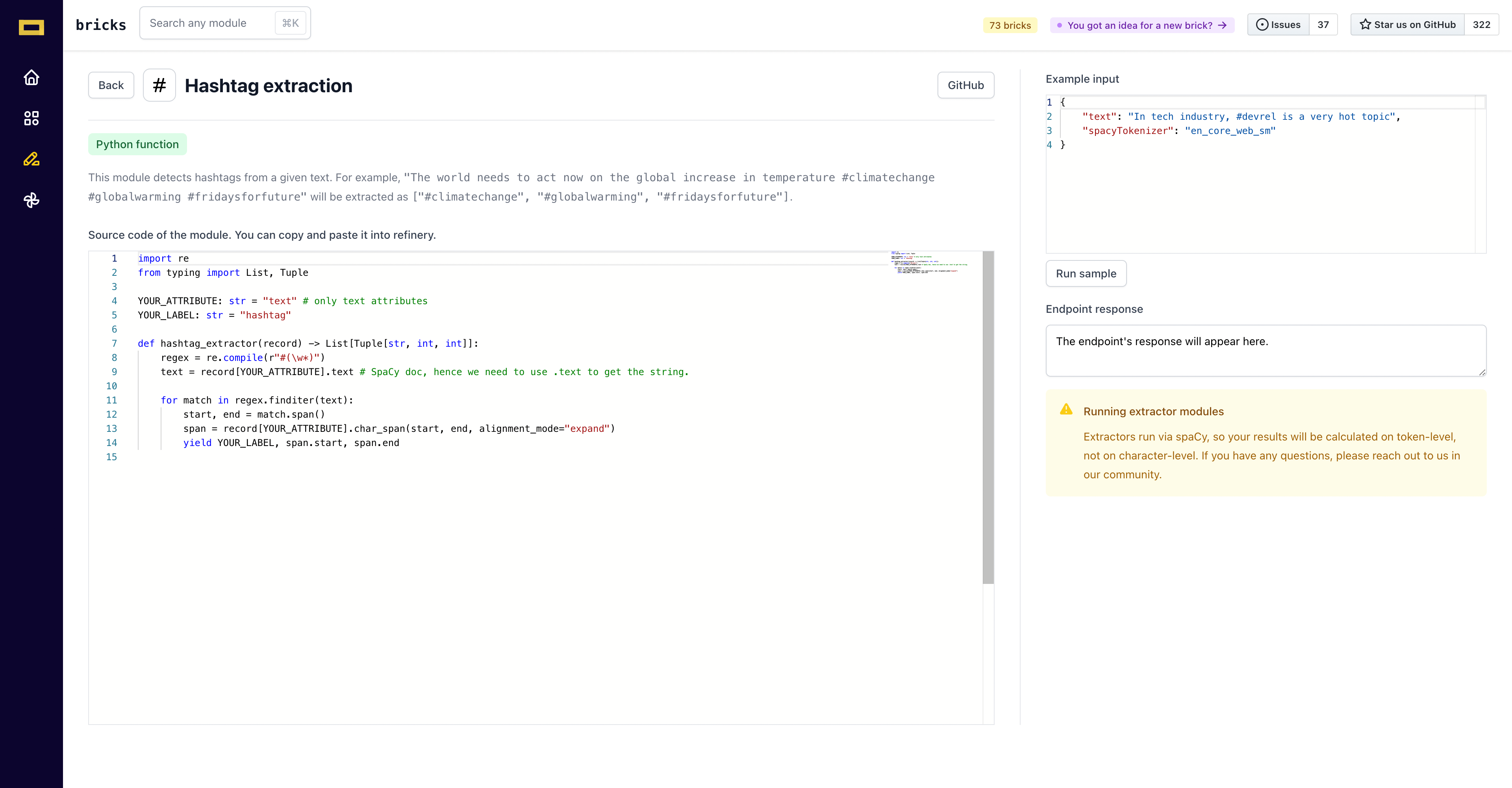
On the right side of the page you can see the input example which requires the text input and, for this case, also the SpaCy tokenizer due to the fact that most of the modules use SpaCy for extraction. The input fields may vary from module to module. In refinery, we support only the en_core_web_sm (English) and de_core_news_sm (German) tokenizers for now. In case you require additional tokenizer, reach out to us at [email protected].
When you click on Run sample the output is generated in the form of a dictionary as shown below
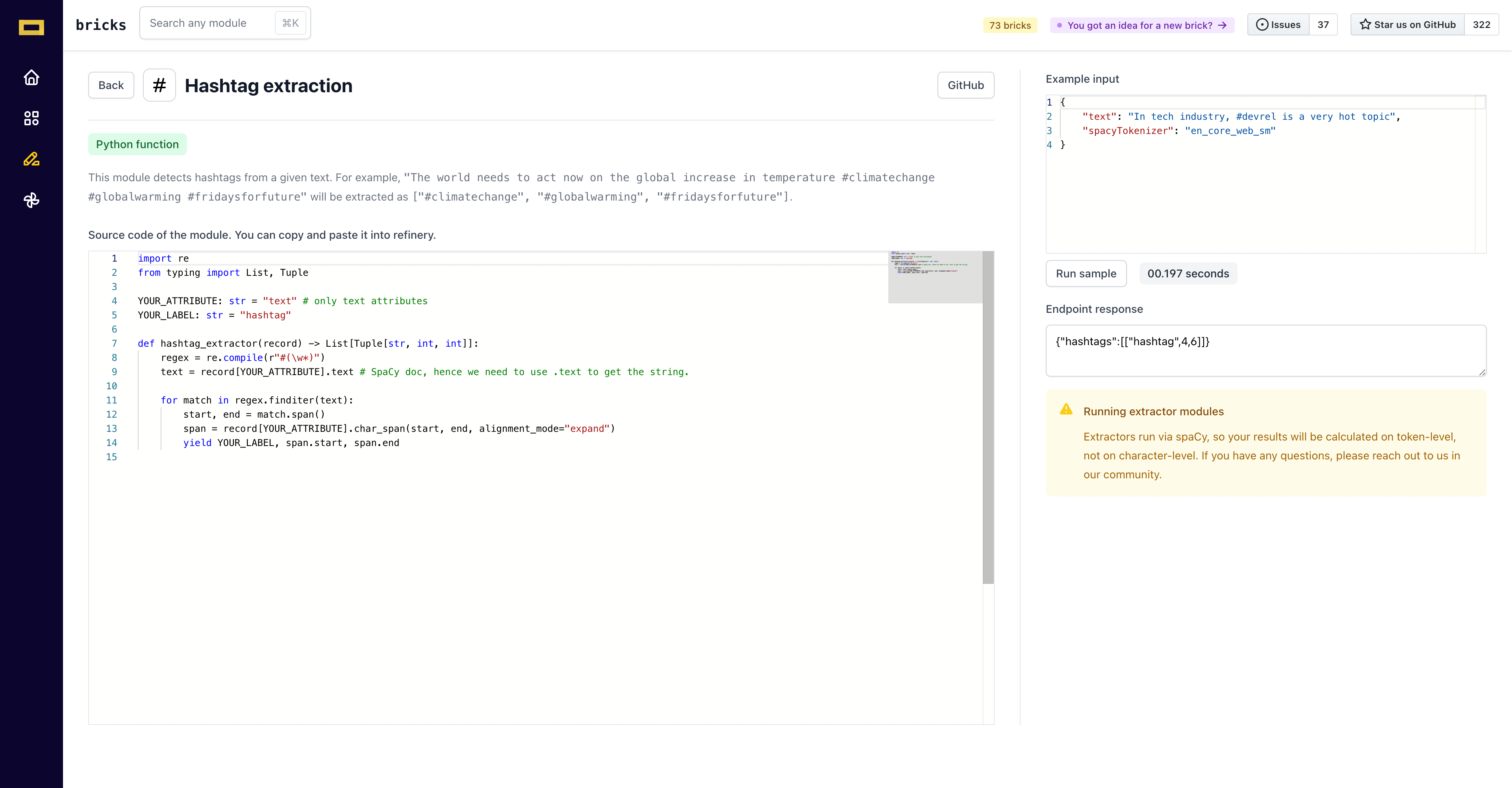
As you can see, the endpoint response returns a dictionary which contains the position of both - the hashtag and the word attached to it, and assigns a label (”hashtag” in this case) to it. In refinery, you can choose your own label when importing the extractor module.
The GitHub button in front of the module name redirects you to the issue
page where, in case of malfunction, you can re-open the issue, or open a new
issue if you come up with a new idea for a extractor.