
Make complex webscraping a breeze
Webscraping is an extremely powerful tool. Still, it can be really difficult to make sense of HTML trees. Have you ever thought about how NLP can help you in webscraping? We did.
Workflow and refinery combined can make your webscraping a lot less headache-causing.
Let's say we want to get the content of some webportal, and structure its content in a way we can later on process it.
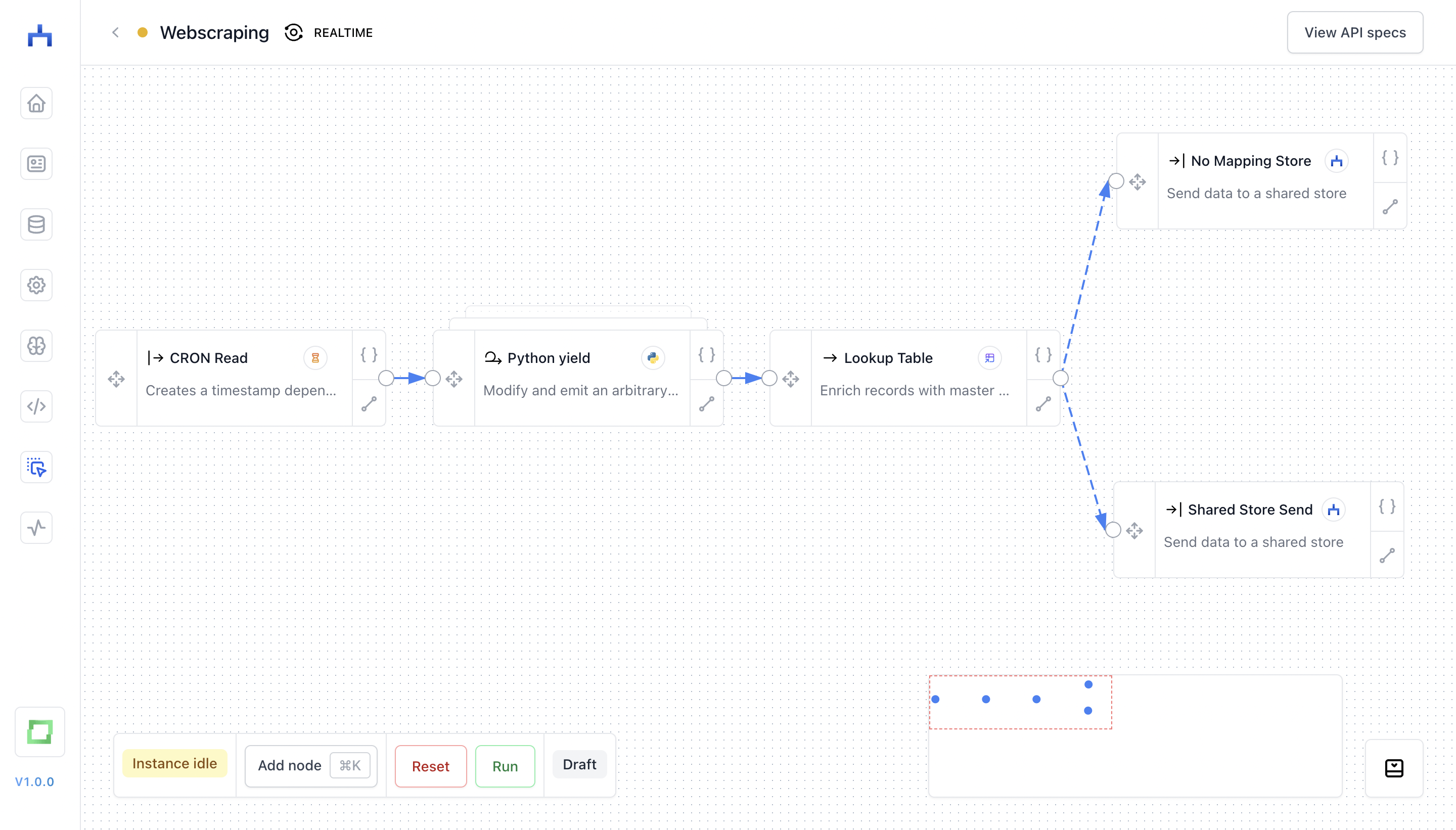
In the above workflow, it looks as follows:
- a simple CRON job triggers the workflow every hour;
- in our "Python yield", we have some scraping logic - via our env variables, you can also store things like access-relevant data, and use them in your scripts;
- the "Python yield" node emits webscraped results to some lookup mapping, e.g. to match 3rd party customer names to the name of your pipeline (think lookups like
"jhoetter" is "[email protected]"), - if a lookup has been found, it is enriched and sent to a shared store
- else, the scraped data is sent to a table to store non-mapped data
Inbetween, you can apply any kind of NLP logic to categorize or structure texts of your webscraped results via gates. By labeling some of the results you'd like to get, you can combine HTML parsing with NLP technologies, making your scraping easier and further reliable.