
Pipeline and automate your training data
Building great training data for your NLP project can be ... difficult. For many reasons, such as:
- having little documentation how the training data was collected and labeled
- having no idea how good the data quality is
- reaching a sufficient training data size
- doing all of this with little structure
Addressing these problems is what refinery was designed for.
Shown in the respective documentation of refinery, you can see how it solves issues like quality assurance, labeling automation or task orchestration. Now, we show you how you can streamline your training data pipeline and ensure that you continuously grow your database.
With workflow, you can synchronize stores with a refinery project, meaning automatically appending training data that is entered into a store to a refinery project. What does this mean? With workflow, you have a full training data engine, capable of chaining complex actions to build your training data over time.
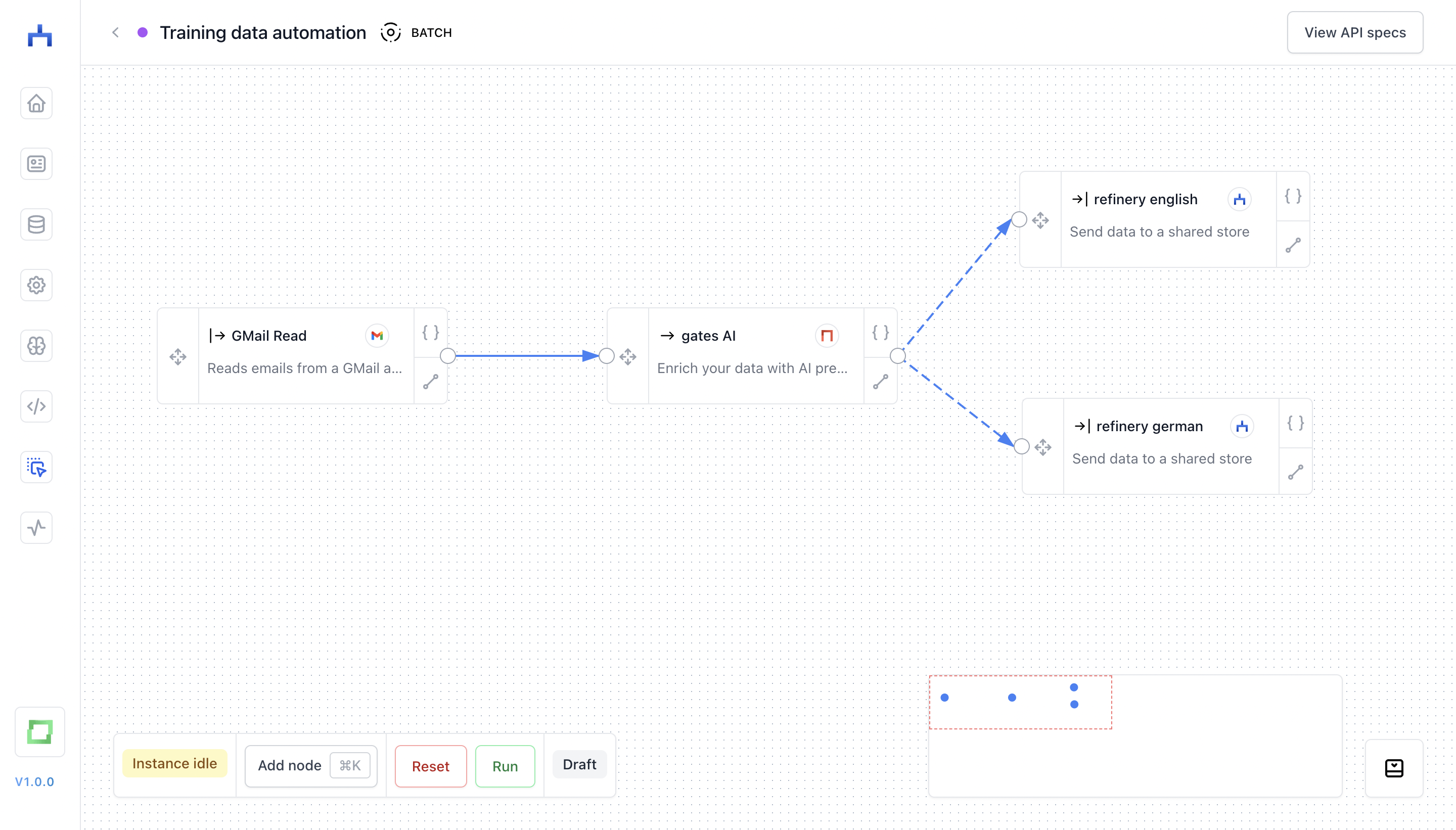
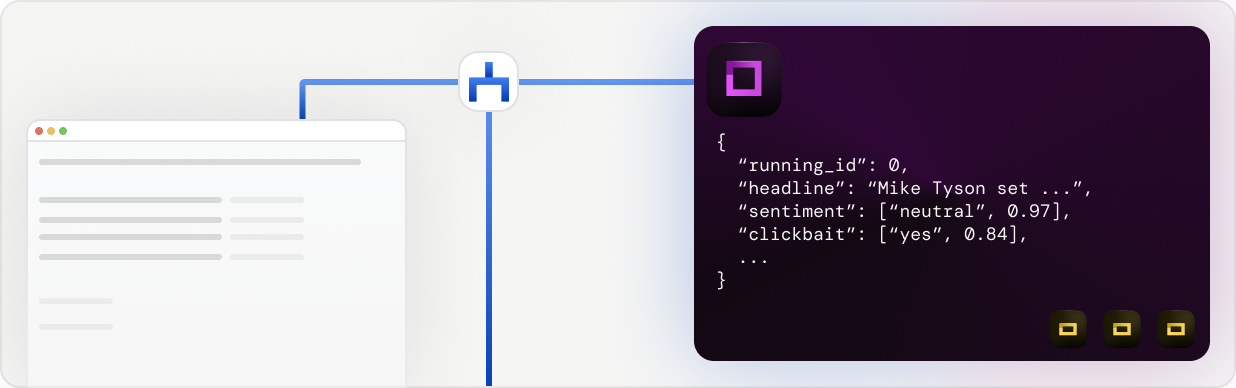
In the above example, you can see
- a Google inbox which is pushing data to a gates model.
- this gates model is analyzing the language of the email,
- and forwards English emails to the English shared store,
- whereas German mails are forwarded to the German shared store.
- both stores are attached to a separate refinery project. This means that your database grows naturally over time!
With workflow, gates and refinery, you can set up training data pipelines of arbitrary complexity - both super simple, or tailored to any requirement you have.