

gates
You've set up a NLP project in refinery and now would like to use it as a realtime API? Say no more. This is gates.
With gates, you get a lightweight add-on to refinery, allowing you to deploy a weakly supervised model within 3 clicks.
Features of gates
gates comes with the following features.
3 clicks to deploy your model
You already did the work in refinery. Now gates is as simple as it gets. Select the automations, hit deploy, and your model is live.
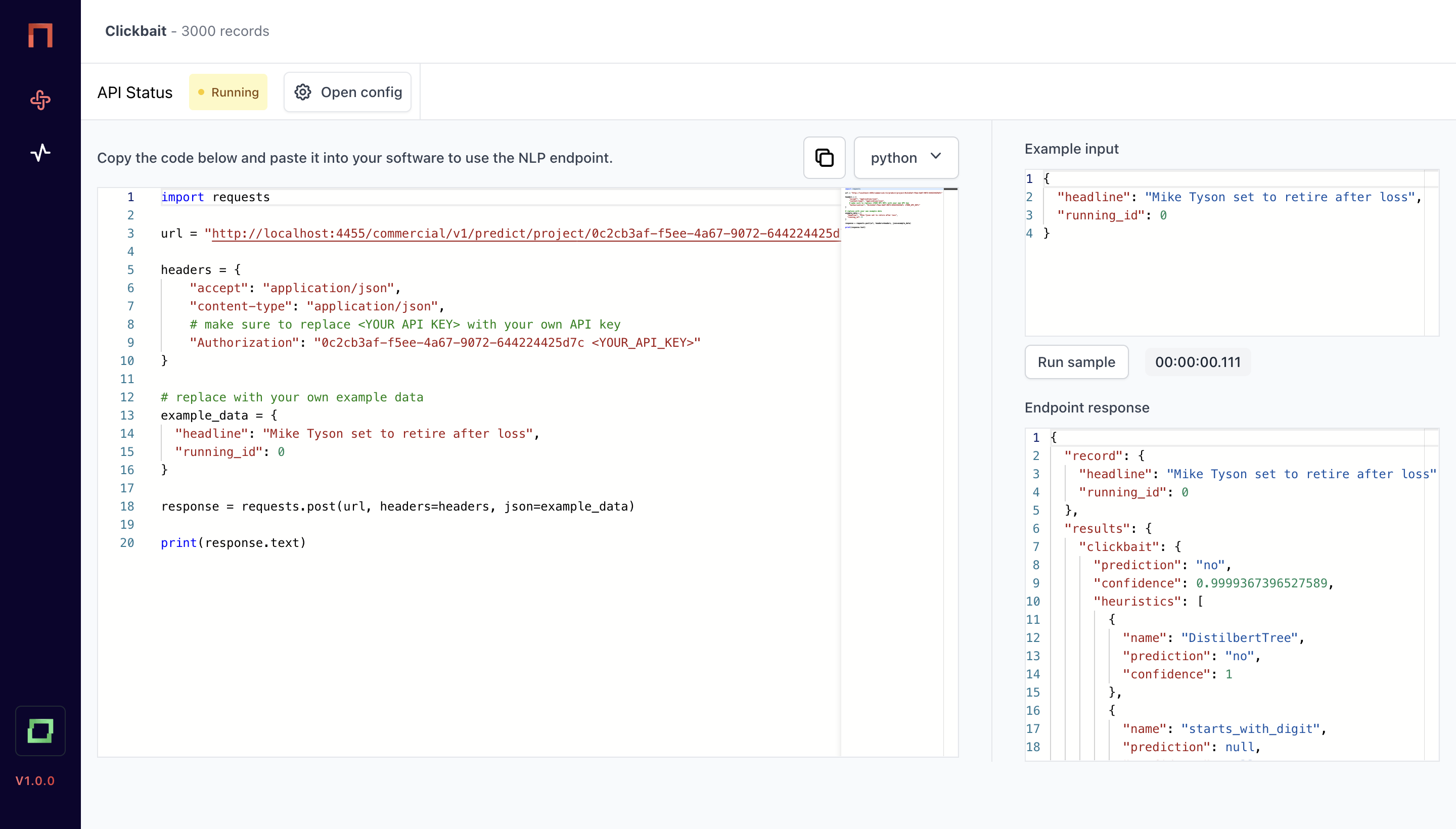
Secure execution - anywhere
Integrate your model into any existing infrastructure. Use the API to get secured access to your model, no matter where and how it is deployed.
Monitor requests per hour, confidence and runtime
Each model comes with a simple monitoring dashboard, helping you to analyze the usage and performance of your model.
Containerized runtime
Your model is deployed as a containerized runtime. If required, you can execute the model on your own infrastructure.